This article contains several patterns and common architectural choices for building software solutions leveraging mostly AWS serverless services.
Why Serverless
Serverless services help us abstract our computing infrastructure so that we can focus solely on business logic.
Even more, When our app is not running we don’t pay for idle server time, but only for what we use. Serverless services scale horizontally & auto-magically and we don’t have to guess our capacity needs upfront.
We can deploy to production quickly, benefiting from zero infrastructure provisioning & maintenance that these services offer.
These services have built-in fault tolerance and support feature deployments without downtime.
Transition to Serverless
In order to enjoy all these benefits, we should try to transition from traditional monolith to microservices with event-driven architectures. This isn’t always an easy transition and requires some changes in how we approach our applications and infrastructure.
We need to start thinking about how we can start decoupling the different services from our monolith and separate responsibilities and roles between them. In the process of “thinking” Serverless, we have to understand tradeoffs for our design choices and use common patterns for event-Driven Architectures & microservices.
Serverless apps use technology-agnostic APIs with decoupled communication. Code is executed in response to events where state and code are decoupled. Integration between components is done via messaging to create asynchronous communication flows.
From monolith to microservices, use the concepts of Domain-driven design to untangle highly coupled applications. The main idea is that we establish a bounded context for each microservice and agree on boundaries between teams & responsibilities.
This way each component can scale independently. Furthermore, your schedule-based tasks could be transformed easily to Lambda functions that run on a schedule for example.
Example Serverless Architectures
Let’s take a look at how we can leverage and combine different AWS Services to build Serverless Architectures.
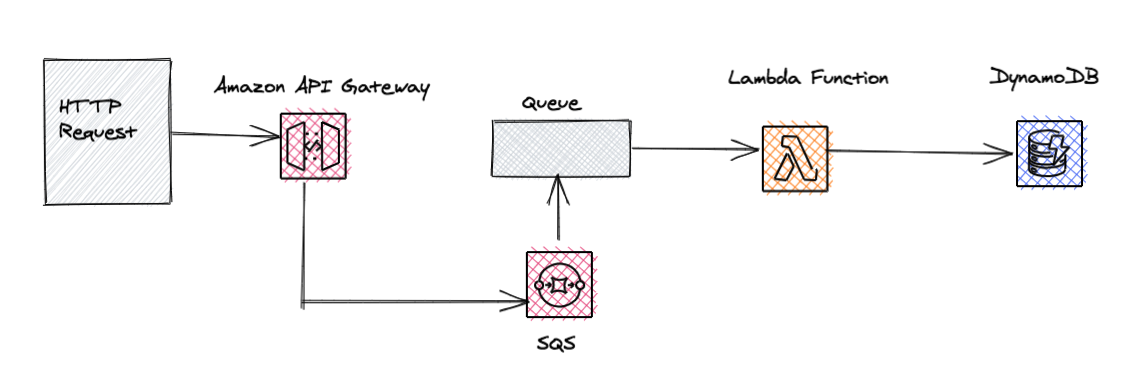
In the above example for a RESTful microservice, the order of information starts with an API call over HTTP. Amazon API Gateway handles the requests and responses accordingly and triggers Lambda that executes the business logic and stores the result in DynamoDB.
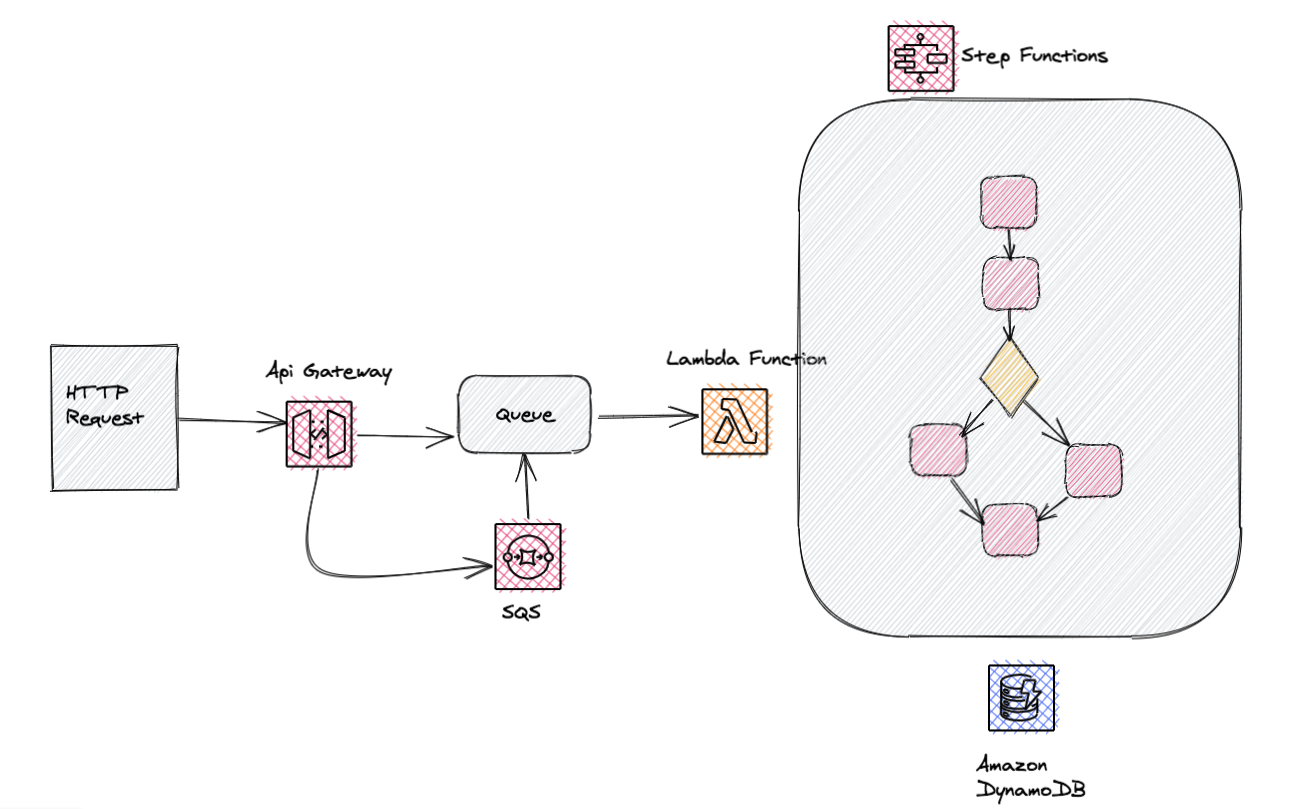
In order to decouple the synchronous connection between Amazon Gateway and Lambda Function, we could use a message queue, SQS.
That has multiple advantages like leveraging built-in retry mechanisms if something fails, the abstraction of Lambda running time, taking care of messages that can’t be processed at the moment, the possibility to add an extra Dead-Letter Queue for messages that fail continuously.
In cases that we have to chain multiple Lambda Functions together we can use Step Functions to orchestrate Lambda workflows and make our life easier since we keep orchestration out of our code, Lambdas are triggered automatically and the state and logs of each step are kept.
This way the Lambda functions are focused only on business logic and Step Functions control the sequence and timing of each task and the state of the whole workflow.
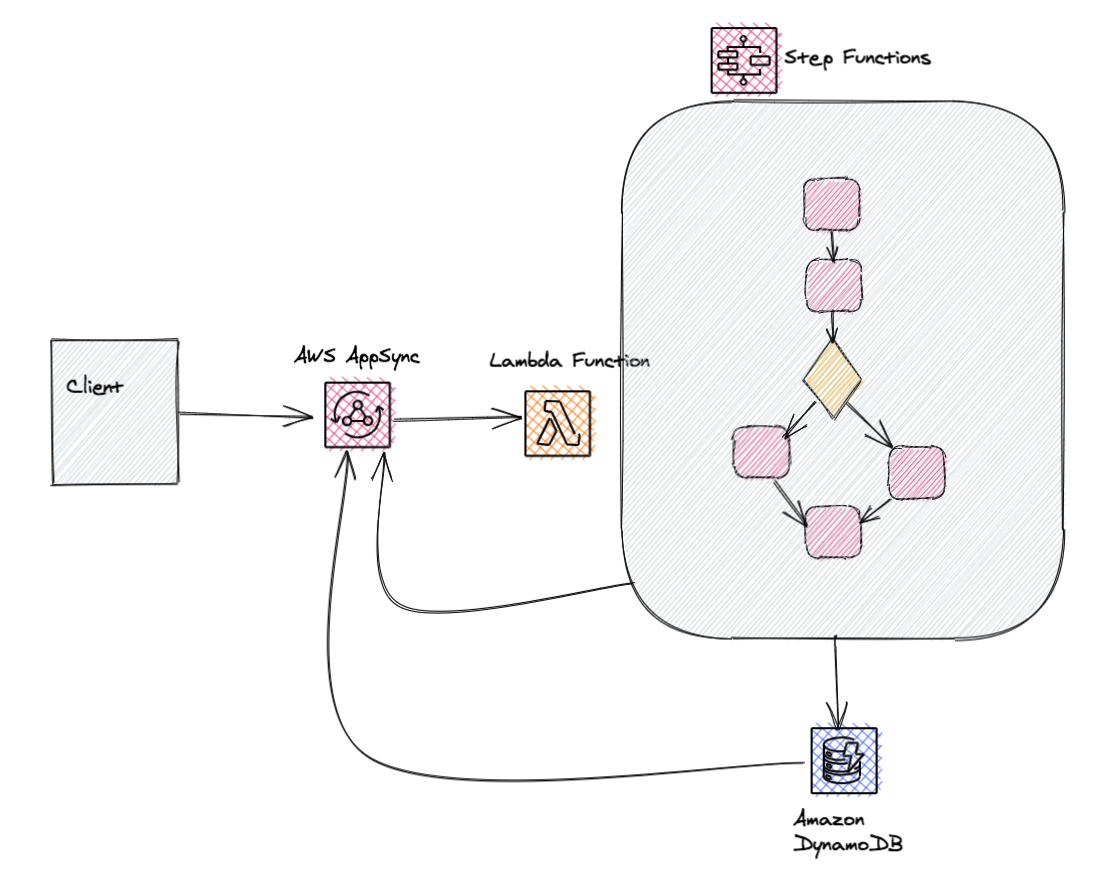
For situations where we need to provide updates to a client regarding the status of a job, we could use a service like AWS AppSync to listen for updates using for example WebSockets with GraphQL subscriptions.
AWS AppSync is a fully managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to data sources like AWS DynamoDB, Lambda, and more.
With AWS AppSync, clients can automatically subscribe and receive status updates as they occur. This is a great pattern when data drives the user interface and is ideal for data that is streaming or may yield more than a single response.
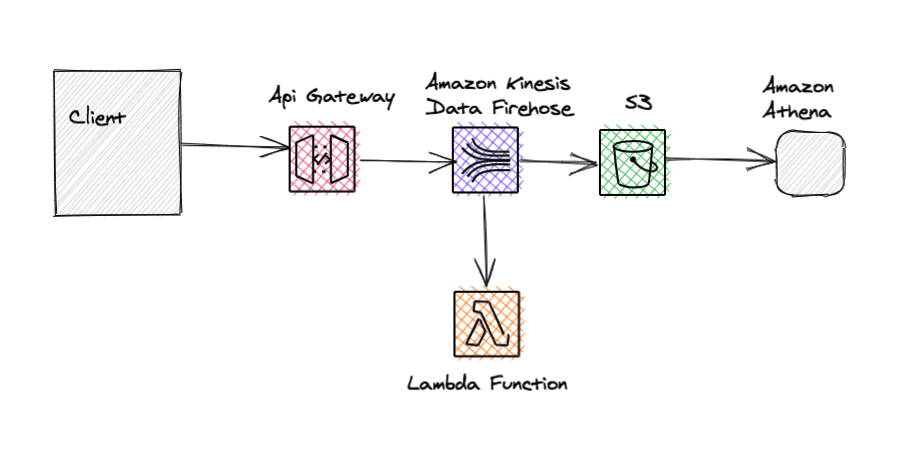
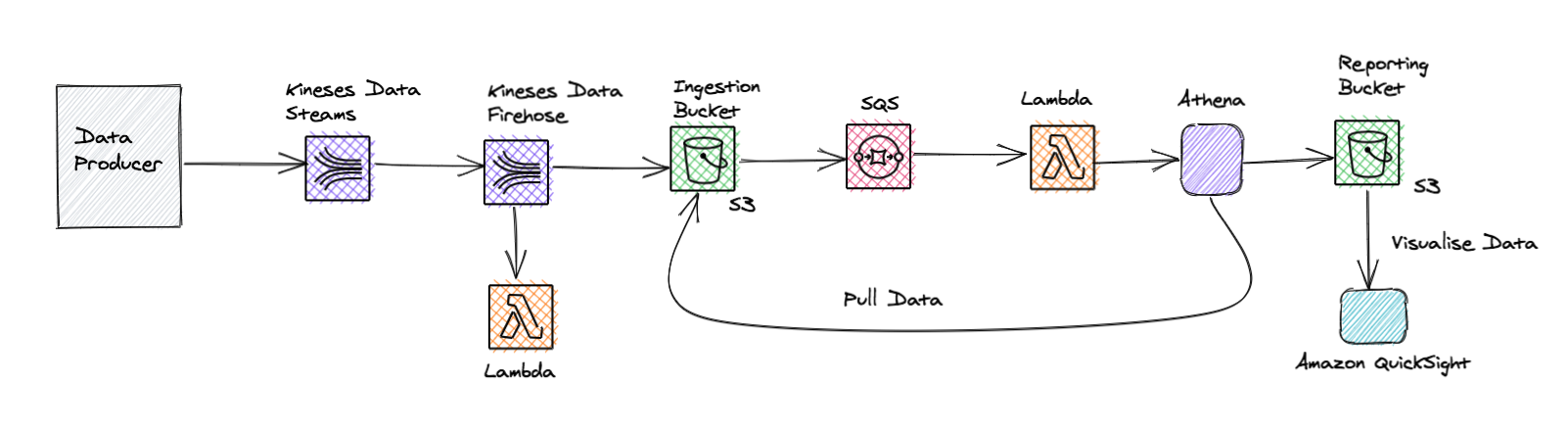
For serverless data processing, we can leverage Amazon Kineses streaming services to ingest and process large volumes of data in near real-time.
For example, we could use Amazon Kinesis Data Firehose to send data and automatically deliver them to the destination that we specify, for example S3.
We could also configure Amazon Kinesis Data Firehose to perform data transformation via specified Lambda Functions as the records are processed, to streamline our architecture. Finally, we could use a tool like Amazon Athena to perform analysis on our stored data.
A similar architecture for a data pipeline could use Kinesis Data streams to get big data in real-time and leverage Kinesis Data Firehose to offload our data in an Amazon ingestion S3 bucket.
The S3 events in our ingestion bucket could be used to send messages to an SQS queue that triggers a Lambda. This Lambda triggers Amazon Athena to query the ingestion S3 bucket and stores the results in a reporting S3 bucket.
Finally, we could use Amazon QuickSight to visualize our data from the reporting S3 bucket
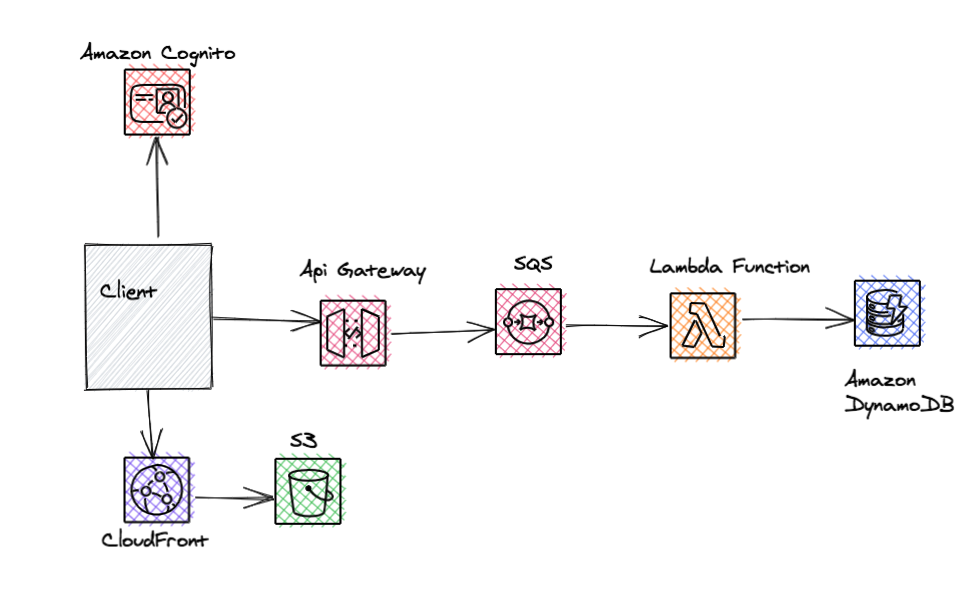
Similar to the pattern we saw earlier (API Gateway, Lambda, SQS, DynamoDB) we can achieve a serverless web application architecture by combining it with Amazon Cognito for authentication, and Amazon S3 and Amazon CloudFront to quickly serve up static content from anywhere.
That’s all folks, hope you enjoyed this. We explored Serverless options, architectures, and common patterns on AWS and explored how we can use and combine different services to benefit from the advantages or Serverless. Let’s start building!