This material was gathered during my preparation for the AWS Solutions Architect Professional Exam. I created and curated this cheatsheet with useful information that will be handy to review before taking the exam.
This article’s objective is to gather different notes, topics and details that I struggled with, and hopefully will help more people get their own badge.
![]()
Use these notes as complementary material and not complete study material for the exam. Check out the official AWS SA Pro study guide for comprehensive information.
AWS frequently changes information, configuration, and options of different services so some of the content might become outdated at some point. Make sure to cross-check and validate the information you are getting from online sources with the official AWS Documentation and FAQs before your exam.
OK enough with the disclaimers, let’s get to it.
Multi Account Strategy
Control Tower
- Setup and govern a secure multi-account AWS environment by orchestrating multiple AWS services(Organizations, Service Catalog, IAM) on your behalf while maintaining the security and compliance needs of your applications.
- Deploy data residency controls and deny data usage outside of specific regions.
- Create a landing zone, a well-architected, multi-account AWS environment based on security and compliance best practices.
- After the landing zone setup, you can configure IAM Identity Center with a supported directory such as AWS Managed Microsoft AD.
- The account factory automates provisioning of new accounts in your organization, preconfigured to meet your needs.
- Guardrails are pre-packaged governance rules for security, operations, and compliance that you can select and apply enterprise-wide or to specific groups of accounts. (SCP, CloudFormation, Config, Dashboard) Mandatory, Preventive, Detective, or Optional.
- Dashboard gives you continuous visibility into your AWS environment.
- Integrates with 3rd party tools to enhance capabilties.
- To migrate accounts to an organization, from the management account, create invitations to other accounts and wait them to accept invitations.
- There is no additional charge to use AWS Control Tower. However, when you set up AWS Control Tower, you will begin to incur costs for AWS services configured to set up your landing zone and mandatory guardrails.
AWS Organizations
- Group accounts into OUs and control access to multiple accounts with IAM Identity
Center(previously SSO) and permissions.
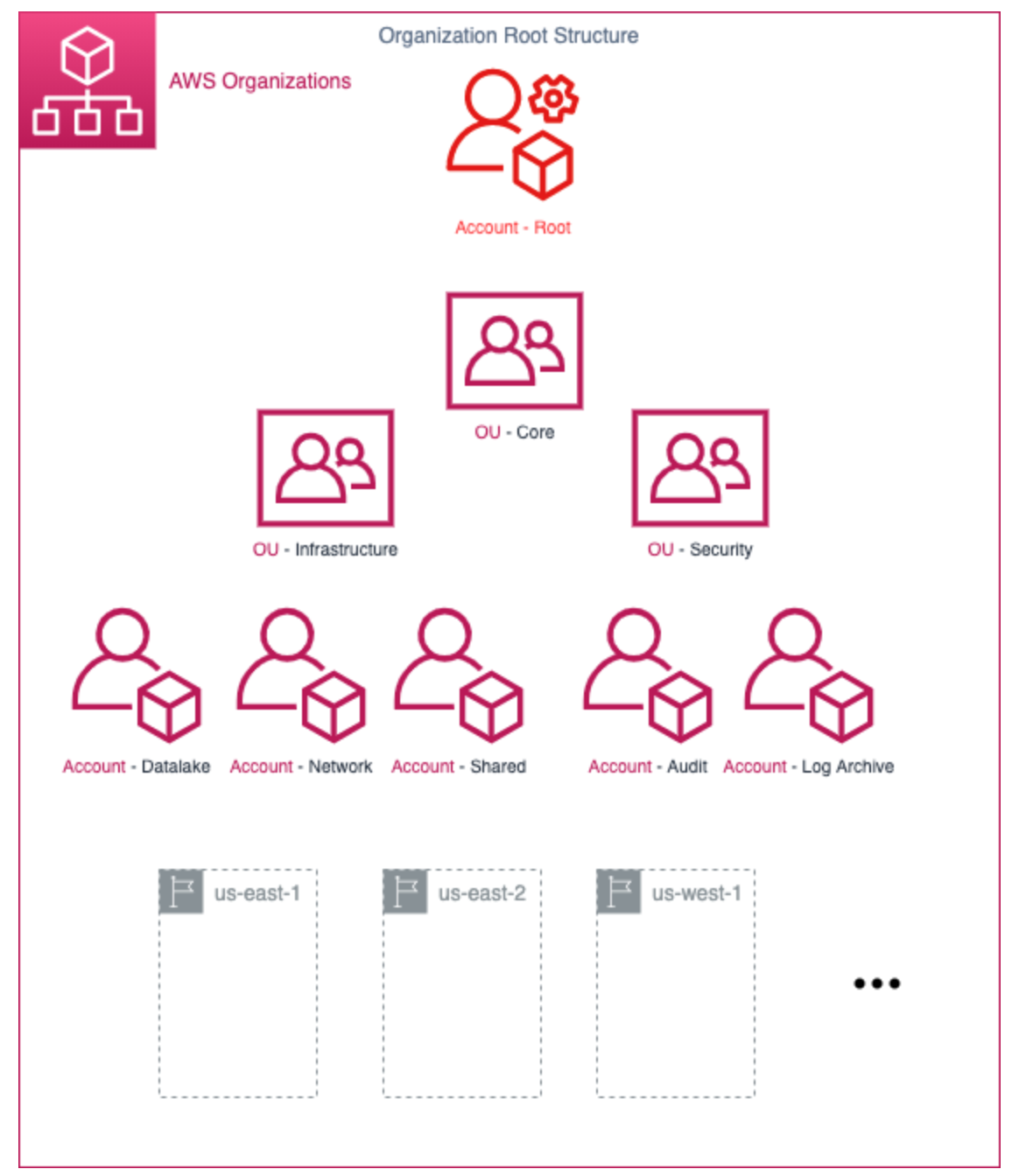
- Service control policies(SCPs) to impose maximum permissions across OUs or accounts(even the root user of the account is restricted).
- Share resources across accounts with RAM.
- Activate Cloudtrail across accounts for audit/compliance purposes.
- AWS Control Tower offers an abstracted, automated, and prescriptive experience on top of AWS Organizations.
- All features mode: prefered way, includes consolidated billing, enabling all features is the default for new orgs, allows advanced account management capabilities.
- Consolidated Billing features: basic management tools, cannot leverage SCPs.
- If a user or role has an IAM permission policy that grants access to an action that is either not allowed or explicitly denied by the applicable SCPs, the user or role can’t perform that action.
- SCPs do not affect any service-linked role.
- AWS strongly recommends that you don’t attach SCPs to the root of your organization without thoroughly testing the impact that the policy has on accounts. Instead, create an OU that you can move your accounts into one at a time, or at least in small numbers, to ensure that you don’t inadvertently lock users out of key services.
- It can work with CloudWatch Events to raise events when administrator-specified actions occur in an organization. For example, because of the sensitivity of such actions, raise a notification for new accounts creation.
- When an invited account joins your organization, you do not automatically have
full administrator controlover the account, unlike created accounts. If you want the master account to have full administrative control over an invited member account, you must create the
OrganizationAccountAccessRoleIAM role in the member account and grant permission to the master account to assume the role.
Resource Access Manager(AWS RAM)
- Enables you to share specified AWS resources that you own with other AWS accounts.
- To enable trusted access with AWS Organizations: From the AWS RAM CLI, use
the
enable-sharing-with-aws-organizationscommand.
Cross Account Access
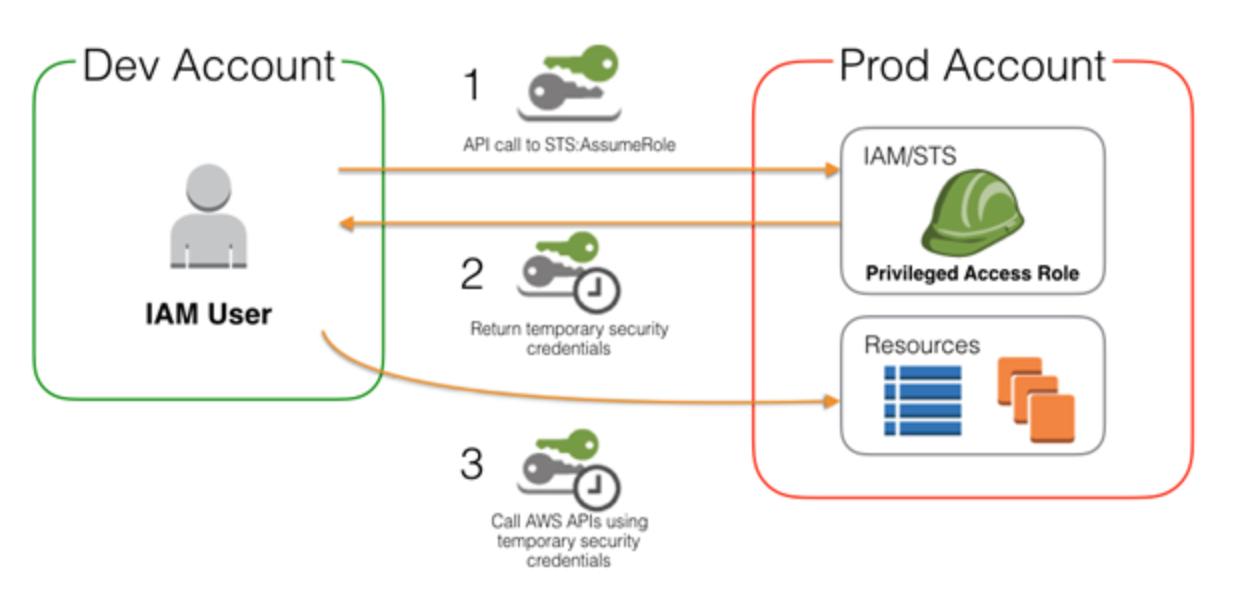
- To access S3 bucket in another account: a) Define an IAM role that allows cross account access with account number of the other account. b) Assign the user on the other account with a policy to be able to assume the role. c) Then the user assumes role. d) The bucket policy must allow this role access.
- To assume role in another account, you can’t switch to a role if you are connected as the root user.
- For some AWS services, you can grant cross-account access to your resources. To do this, you attach a policy directly to the resource that you want to share, instead of using a role as a proxy. The resource that you want to share must support resource-based policies. Unlike a user-based policy, a resource-based policy specifies who (in the form of a list of AWS account ID numbers) can access that resource.
- With a resource that is accessed through a resource-based policy, the user still works in the trusted account and does not have to give up his or her user permissions in place of the role permissions. In other words, the user continues to have access to resources in the trusted account at the same time as he or she has access to the resource in the trusting account. This is useful for tasks such as copying information to or from the shared resource in the other account.
- At times, you need to give a third-party access to your AWS resources (delegate access). One important aspect of this scenario is the External ID, optional information that you can use in an IAM role trust policy to designate who can assume the role.
Tagging
- Use to organize resources. Helps with billing to break down costs, automation, and acces control.
- Tag Categories (technical tags, business tags, tags for automation, security tags).
- Best practices: standardized, case-sensitive, consistent across resources, leverage tools(resource groups).
Disaster Recovery
Disaster Recovery Strategies
- Pilot Light → DBs ready and data replication, create other resources when it’s time(VMs).
- Warm Standby → DBs ready and data replication, other resources operational but scaled down.
- The difference between Pilot Light and Warm Standby can sometimes be difficult to understand. Both include an environment in your DR Region with copies of your primary region assets. The distinction is that Pilot Light cannot process requests without additional action taken first, while Warm Standby can handle traffic (at reduced capacity levels) immediately.
Elastic Disaster Recovery
- Minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal compute, and point-in-time recovery.
- Use cases: a) On-premises to AWS b) Cloud to AWS c) AWS Region to AWS Region
Identity and Access Management
AWS IAM Identity Center
- Supports only SAML 2.0–based applications so an OpenID Connect-compatible solution will not work.
Simple AD
- Subset of Microsoft AD.
Managed Microsoft AD
- Configure a trust relationship between AWS Managed Microsoft AD in the AWS Cloud and your existing on-premises Microsoft Active Directory, providing users and groups with access to resources in either domain, using single sign-on (SSO).
Microsoft AD connector
- In case you want to connect to on premises AD.
Identity Federation
- Identity federation with SAML 2.0 enables federated single sign-on (SSO). You can
use a third-party SAML IdP to establish SSO access to the console or you can create a custom IdP to enable console access for your external users.
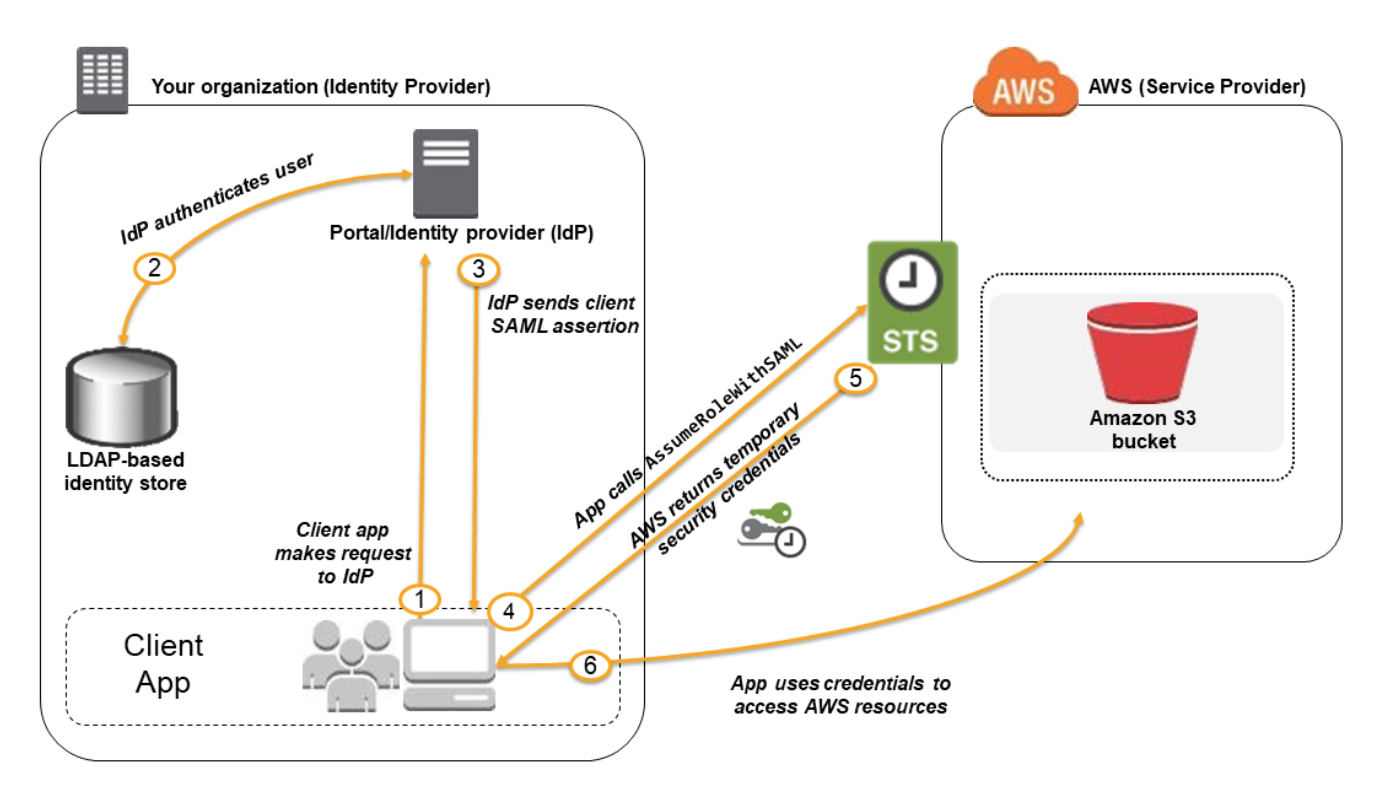
- Before you can use SAML 2.0-based federation, you must configure your organization’s IdP and your AWS account to trust each other. Inside your organization, you must have an IdP that supports SAML 2.0, like Microsoft Active Directory Federation Service (AD FS, part of Windows Server). In your organization’s IdP, you define assertions that map users or groups in your organization to the IAM roles.
- When you create the trust policy for the role, you specify the SAML provider that you created earlier as the Principal.
- Flow: LDAP → STS → AWS access.
- Web Identity Federation with
AssumeRoleWithWebIdentityAPI → STS → AWS resources.
Create SAML Identity provider in IAM
- Get the SAML metadata document from IdP.
- Create SAML IAM identity provider.
- Configure SAML IdP with relying party trust.
- In IdP, configure SAML Assertions for the authentication response.
Cognito
- Authorization, authentication sign-up and sign-in features, user management for mobile and web.
- Scales to millions of users.
- User pools: sign in, sign up, can use other providers(Google, FB, Amazon), MFA
- Login via social identity providers, such as Apple, Facebook, Google, and Amazon and enterprise identity providers via SAML and OIDC.
- Identity pools: Create unique identities and assign permissions for users, obtain temporary AWS credentials with permissions you define to directly access other AWS services or to access resources through Amazon API Gateway.
- For unauthenticated users, enable unauthenticated access in Cognito Identity Pool. Guest users can request an identity ID via the GetId API.
- In Cognito User Pool, you can configure users in groups to manage the permissions better. Each group can be linked with an IAM Role.
- If you don’t use Amazon Cognito, then you choose to write a custom code or app that interacts with a web IdP (Login with Amazon, Facebook, Google, or any other OIDC-compatible IdP) and then call the
AssumeRoleWithWebIdentityAPI to trade the authentication token you get from those IdPs for AWS temporary security credentials. - Pricing based on your monthly active users.
IAM Roles
- Trust relationship: Defines which service/user can assume the role.
AssumeRoleaction via STS, configurable min 15mins, max 12hours.- IAM roles can have a policy attached to define services that can be accessed by the role’s temporary creds.
- When you assume a role, you give up your original permissions and take the permissions of the assigned role.
Service role
- A service role is an AWS Identity and Access Management (IAM) that grants permissions to an AWS service so that the service can access AWS resources.
Networking
VPC
- A
transit VPCis a common strategy for connecting multiple, geographically disperse VPCs and remote networks in order to create a global network transit center. Transit VPC uses customer-managed Amazon Elastic Compute Cloud (Amazon EC2) VPN instances in a dedicated transit VPC with an Internet gateway. This design requires the customer to deploy, configure, and manage EC2-based VPN appliances, which will result in additional EC2 instances, and potentially third-party product and licensing charges. Enables more complex routing rules, such as network address translation between overlapping network ranges, or to add additional network- level packet filtering or inspection.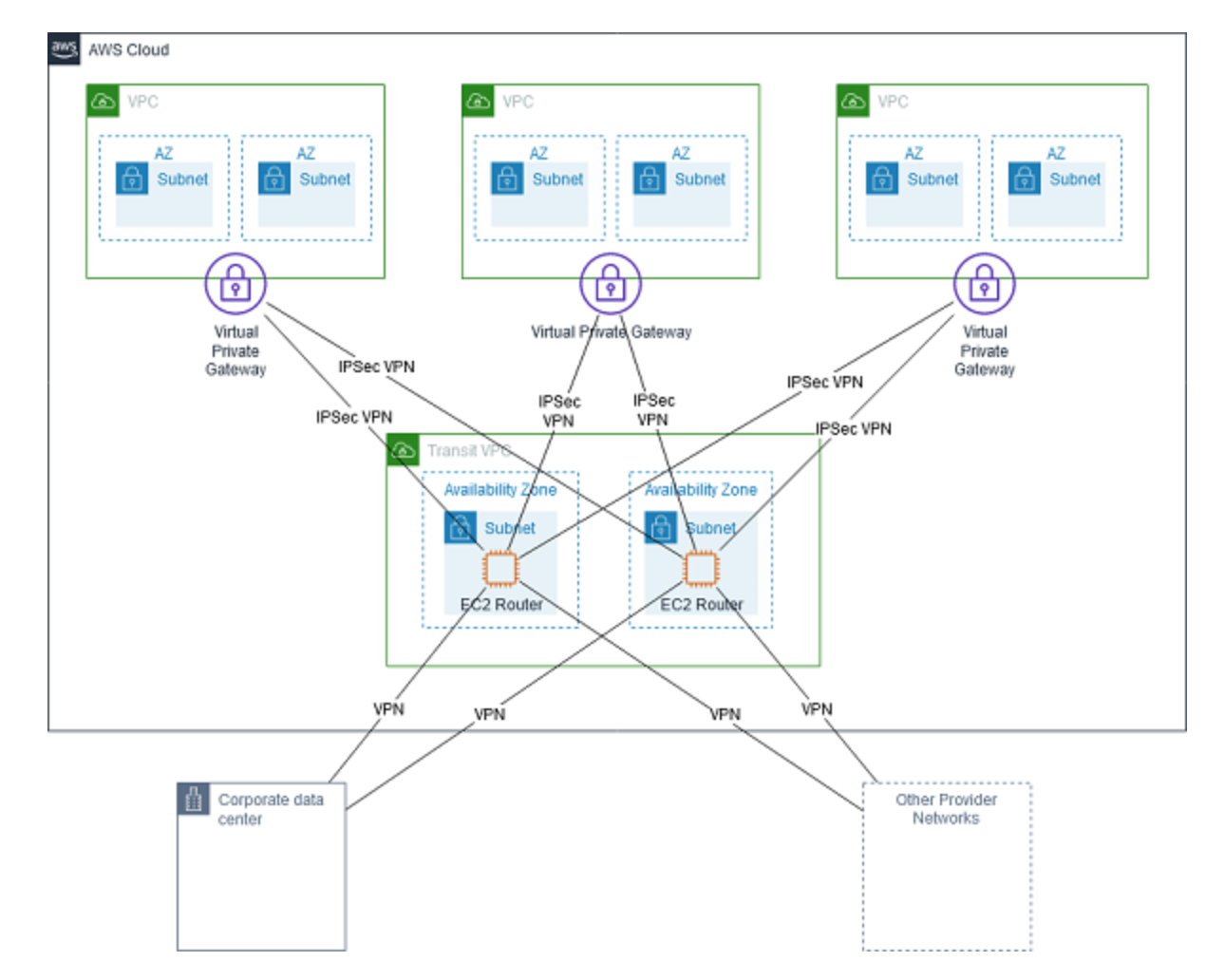
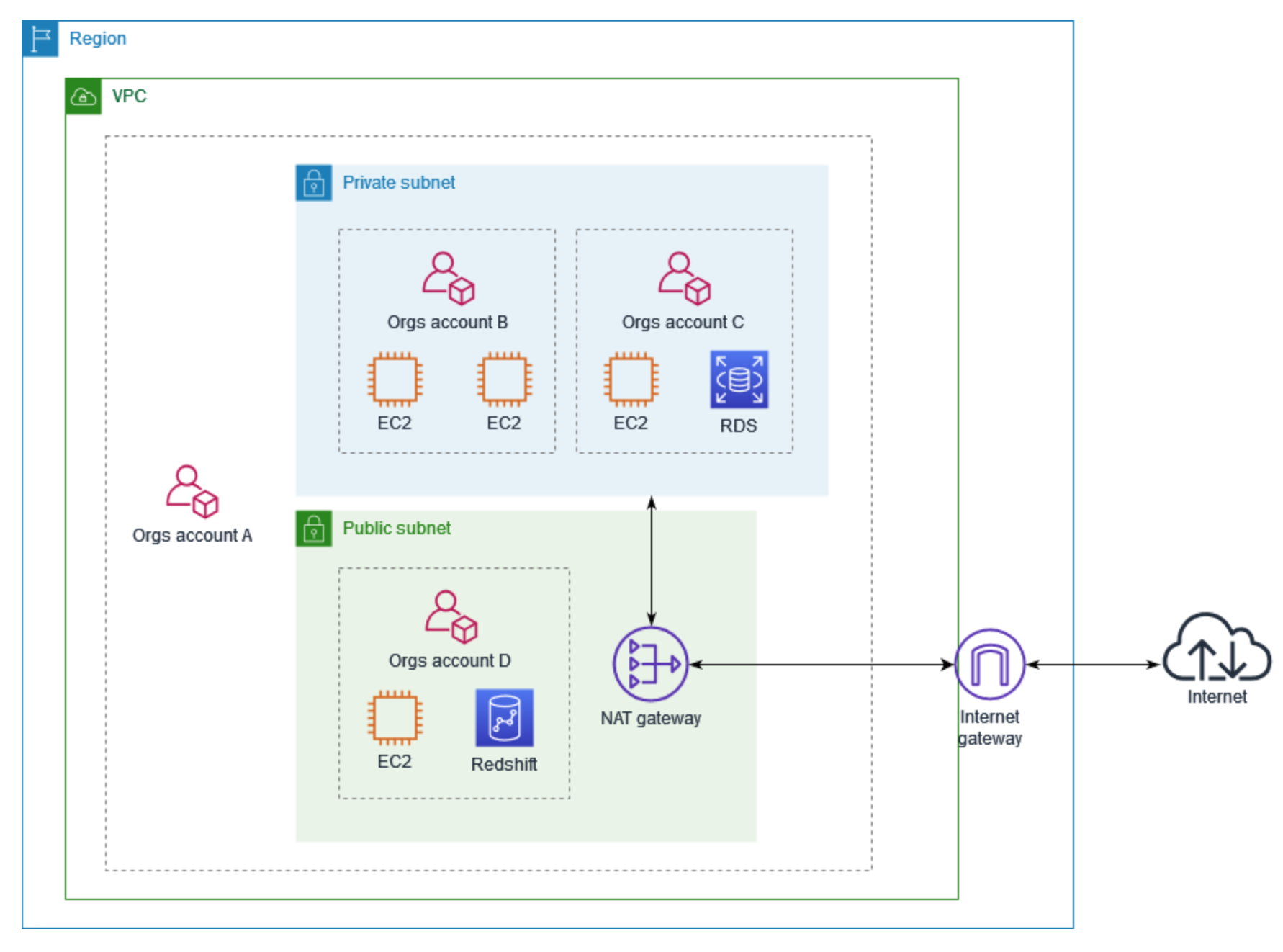
- When deploying distributed architectures, a popular approach is to build a
shared services VPC, which provides access to services required by workloads in each of the VPCs. This might include directory services or VPC endpoints. Sharing resources from a central location instead of building them in each VPC may reduce administrative overhead and cost. - VPC sharing (part of Resource Access Manager) allows multiple AWS accounts to
create their application resources in the same VPC(shared by the VPC owner). The
account that owns the VPC (owner) shares one or more subnets with other accounts
(participants) that belong to the same organization.
- You can’t have a VPC with only a public subnet and AWS Site-to-Site VPN.
- AWS reserves 5 Ip addresses in each subnet. The first 4 and the last one
- To add IPv6 to VPC: a) Associate IPv6 CIDR block. b) Create Egress-only Internet Gateway for private subnets. c) Assign IPv6 addresses to EC2 instances from the IPv6 address range
- Possible to expand existing VPC by adding a secondary IPv4 range.
- Fixed MAC address for EC2 → use case for ENI.
- Once you create DHCP options, you cant modify them.
- Use Traffic Mirroring to copy network traffic from an elastic network interface of type
interface. You can then send the traffic to out-of-band security and monitoring appliances for content inspection, threat monitoring, network tourbleshooting.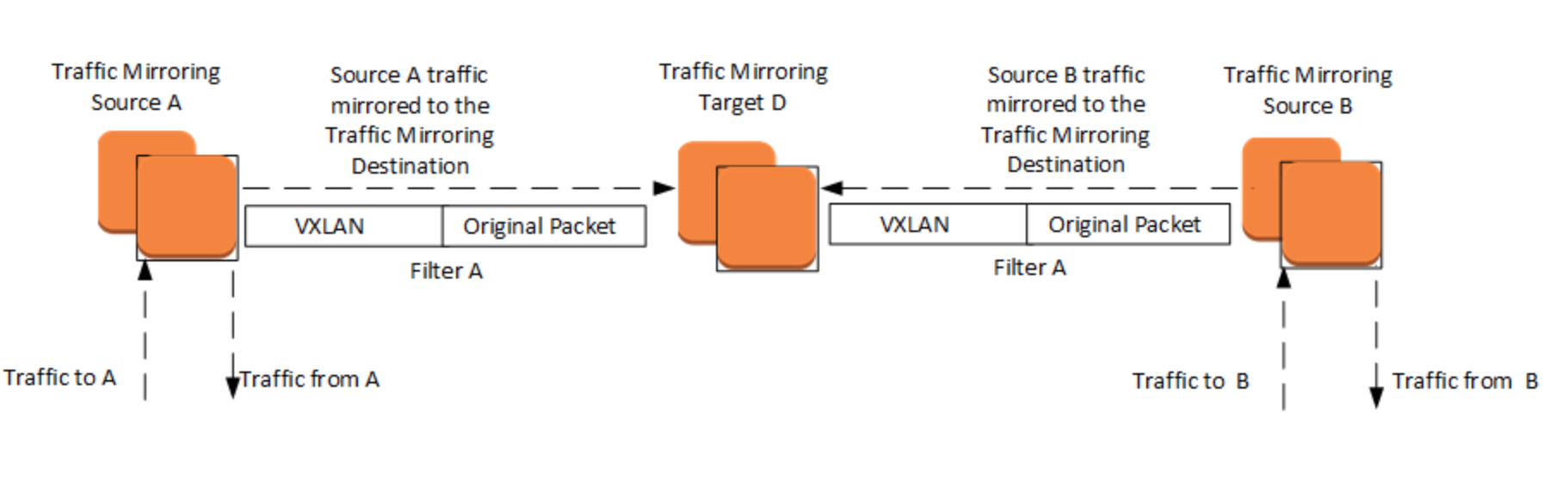
- AWS uses the longest prefix matching to determine where traffic should be routed.
- Access to interface endpoint: configured through AWS VPN connections or Direct Connect connections, through intra-region VPC peering connections and through inter-region VPC peering connections from any type of instance. You can add endpoint policies to interface endpoints that define which principal can perform which actions on which resources. An endpoint policy does not override or replace IAM user policies or service-specific policies. It is a separate policy for controlling access from the endpoint to the specified service.
- An interface endpoint, except for an Amazon S3 interface endpoint, has a corresponding private Domain Name System (DNS) hostname.
- You can limit outbound web connections from your VPC to the internet, using a web proxy (such as a squid server) with custom domain whitelists or DNS content filtering services.
NACL
- A common use-case is to allow ephemeral ports in NACLs to handle response traffic.
Transit Gateway
- Acts as a Regional virtual router for traffic flowing between your virtual private clouds (VPCs) and on-premises networks.
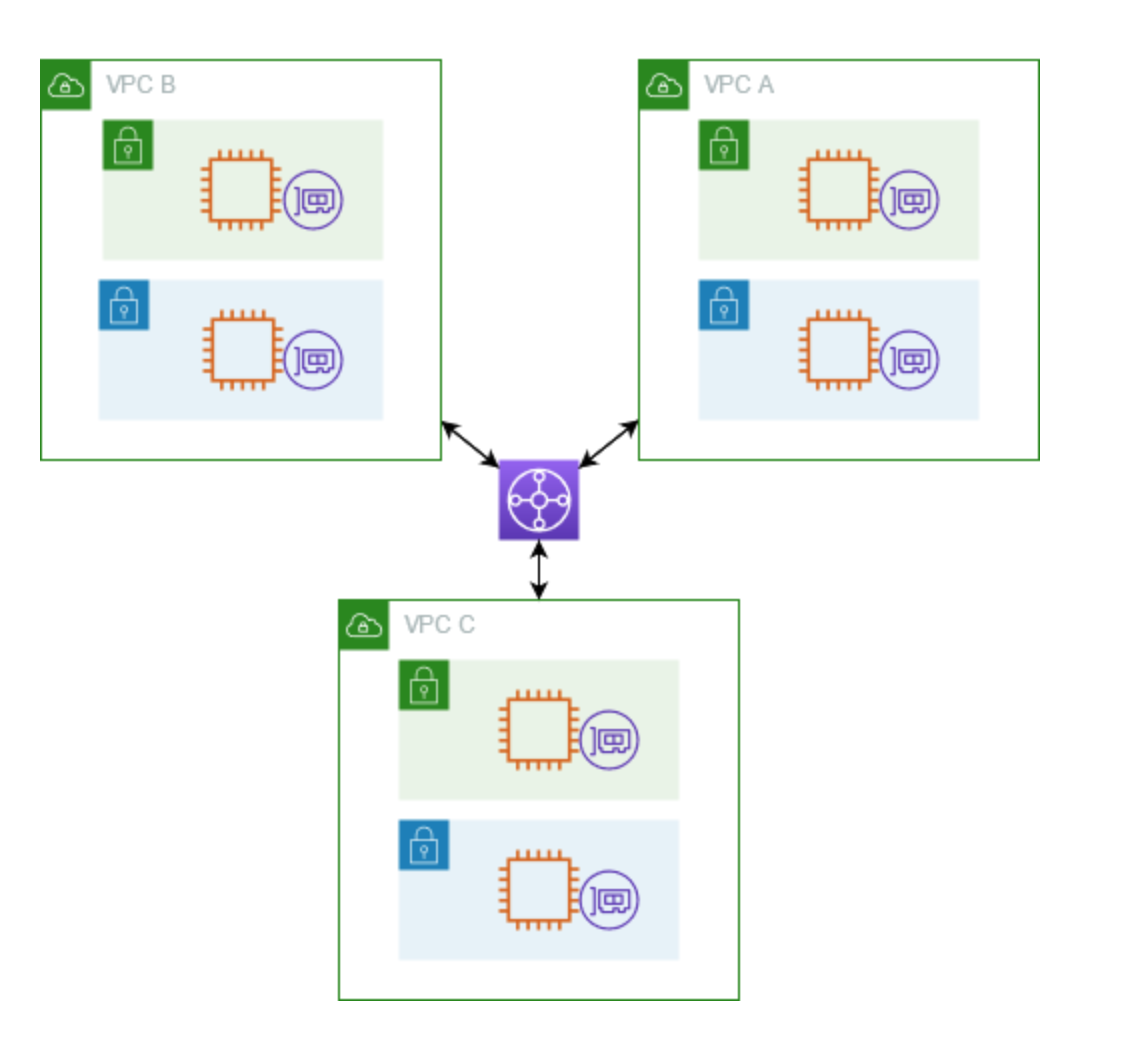
- TGW supports multicast.
NAT Instance
- When there is a connection time out, a NAT instance sends a FIN packet to resources behind the NAT instance to close the connection. It does not attempt to continue the connection which is why some connections might be failing.
AWS Direct Connect
- Combine Direct Connect & VPN for an IPsec-encrypted private connection.
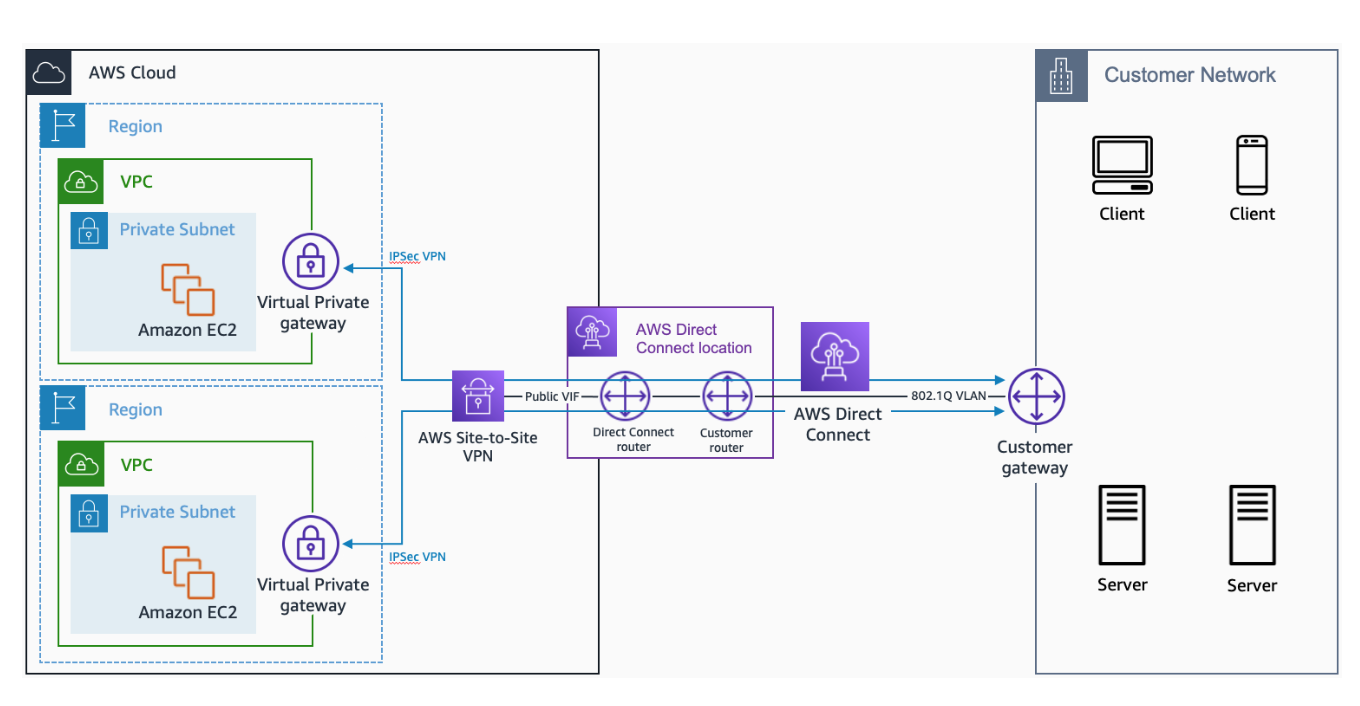
- Establish an AWS VPN over an AWS Direct Connect connection:
a) Create your Direct Connect connection.
b) Create a public virtual interface for your Direct Connect connection. For
Prefixesyou want to advertise, enter your customer gateway device’s public IP address and any network prefixes that you want to advertise. Note: Your public virtual interface receives all AWS public IP address prefixes from each AWS Region (except the AWS China Region). These include the public IP addresses of AWS managed VPN endpoints. c) Create a new VPN connection. Be sure to use the same customer gateway’s public IP address that you used in the previous step.Note: You can configure the customer gateway in Border Gateway Protocol (BGP) with an Autonomous System Number (ASN). d) Configure your VPN to connect to your VPC. For example configurations, see tutorials for creating VPCs. - For hybrid network architecture that is highly available and supports high bandwidth, configure the Direct Connect based hybrid network to achieve maximum resiliency for critical workloads by using separate connections from different service providers that terminate on separate devices in more than one location.
- For a cheap backup alternative of DX, configure backup hardware VPN connection as a failover option.
- To connect to services such as EC2 using just Direct Connect, you need to create a private virtual interface.
- If you want to encrypt the traffic flowing through Direct Connect, you will need to use the public virtual interface of DX to create a VPN connection.
- Configure a public virtual interface from the Direct Connect connection to connect to AWS resources that are reachable by a public IP address (such as an S3 bucket).
- With a public virtual interface, you can: a) Connect to all AWS public IP addresses globally. b) Create public virtual interfaces in any DX location to receive Amazon’s global IP routes c) Access publicly routable Amazon services in any AWS Region (except for the AWS China Region).
- With a private virtual interface, you can: a) Connect VPC resources (such as Amazon Elastic Compute Cloud (Amazon EC2) instances or load balancers) on your private IP address or endpoint. b) Connect a private virtual interface to a DX gateway. Then, associate the DX gateway with one or more virtual private gateways in any AWS Region (except the AWS China Region). c) Connect to multiple VPCs in any AWS Region (except the AWS China Region), because a virtual private gateway is associated with a single VPC.
AWS Site-to-Site VPN
- To create the customer gateway resource in AWS: a) The internet-routable IP address for the devic’s external interface. b) The type of routing: static or dynamic. c) For dynamic routing, the Border Gateway Protocol (BGP) Autonomous System Number (ASN).
Migrations
- Use the AWS Cloud Adoption Readiness Tool (CART) to generate a migration assessment report to identify gaps in organizational skills and processes.
Migration Hub
- Central place to visualize migration process including the discovery phase.
- Provides key metrics and progress for individual applications, regardless of which tools are being used to migrate them.
AWS Application Migrations Service
- Highly automated lift-and-shift (rehost) solution that simplifies, expedites, and reduces the cost of migrating applications to AWS.
- The first setup step for Application Migration Service is creating the Replication Settings template. Add source servers to Application Migration Service by installing the AWS Replication Agent (also referred to as the Agent) on them. The Agent can be installed on both Linux and Windows servers.
AWS Application Discovery Service
- Helps you plan your migration to the AWS cloud by collecting usage and configuration data about your on-premises servers.
- Integrates with Migration Hub.
- Agenteless Discovery with the Application Discovery Service Agentless Collector through your VMware vCenter. Collects IPs, hostnames, MAC addresses, disk resource allocation, utilization data, and computes average and peak for CPU, RAM, disk I/O.
- Agent-based discovery by deploying the Application Discovery Agent(windows and linux) on each of your VMs. Collects static configuration data, system performance, I/O network connections, and running processes.
- Data exploration in Amazon Athena allows you to analyze the data collected from all the discovered on-premises servers by Discovery Agents in one place.
AWS Server Migration Service(SMS)
- An agentless service for migrating thousands of on-premises workloads to AWS
- Each server volume replicated is saved as a new Amazon Machine Image (AMI).
- AWS SMS creates a new EBS snapshot with every replication. It replicates server volumes from your on-premises environment to S3 temporarily and purges them from S3 right after creating EBS snapshots.
AWS DataSync
- Simplifies and accelerates data migrations to AWS as well as moving data between on-premises storage, edge locations, other clouds, and AWS Storage.
- Can move data directly to Glacier or Glacier Deep Archive.
- Uses an agent to read and write data from your storage systems. A single DataSync agent is capable of saturating a 10 Gbps network link.
- Connects with standard protocols: Network File System (NFS), SMB, or the Amazon S3 API.
- It comes with retry and network resiliency mechanisms, network optimizations, built-in task scheduling, monitoring.
- Natively integrated with Amazon S3, Amazon EFS, Amazon FSx for Windows File Server, Amazon CloudWatch, and AWS CloudTrail.
- Use DataSync to migrate existing data to S3 & storage gw(e.g. file gw) to retain access to migrated data & ongoing updates from on-premises.
- A 1Gbps connection at full utilization can transfer approximately 10 TB of data in a day.
Storage Gateway
- Hybrid cloud storage service that provides on premises access and cloud storage with Amazon S3.
- Storage Gateway doesn’t automatically update the cache when you upload a file directly to Amazon S3. Perform a RefreshCache operation to see the changes on the file share.
- Storage Gateway uses an appliance that is installed and hosted on premises as a VM appliance, as a hardware appliance, or in AWS as an Amazon Elastic Compute Cloud (Amazon EC2) instance.
- Connects using standard protocols Internet Small Computer System Interface (iSCI),SMB, and NFS.
- Low RTO and RPO for offline backups.
- Storage Gateway uses Challenge-Handshake Authentication Protocol (CHAP) to authenticate iSCSI and initiator connections.
File Gateway
- SMB or NFS access to data in S3 with local caching.
Volume Gateway
- Present cloud-based iSCSI block storage volumes to your on-premises applications.
- With cached volumes, the AWS Volume Gateway stores the full volume in its Amazon S3 service bucket, and just the recently accessed data is retained in the gateway’s local cache for low-latency access.
- Can create point in time snapshots on EBS of gateway volumes.
- Gateway-Cached volumes can support volumes of 1,024TB in size
- Gateway-stored volume supports volumes of 512 TB size.
Tape Gateway
- Supports archiving directly to Glacier and Glacier Deep Archive.
AWS AppSync
- Store and sync data across mobile and web apps in real-time.
AWS AppFlow
- Automate data flows between software as a service (SaaS) and AWS services.
DMS
- DMS data validation to ensure that your data has migrated accurately from the sourceto the target.
- KMS encrypts data in the replication instance. The master key is aws/dms by default or a customer managed key(CMK).
- For unsupported DB sources, export data to CSV, load to S3, configure table definition JSON doc.
- DMS Fleet Advisor will help to discover our data infrastructure.
- DMS Schema Conversion or the AWS Schema Conversion Tool (AWS SCT) to automatically assess and convert schemas.
- For heterogeneous database migrations, two-step process. Use AWS Schema Conversion Tool to convert the source schema and code to match the target DB, then use DMS to migrate data from the source to the target DB.
Snowball
- Up to 80TB, good choice if you have limited bandwidth.
- Good choice for up to single digit PB with multiple devices.
- If you have less than 10TB probably not the best/cheapest choice.
- Data encrypted on device.
- The AWS Snowball has a typical 5-7 days turnaround time.
Snowball edge
- Onboard compute power for edge-computing.
- ~100TB
- You can’t directly copy data from Snowball Edge devices into AWS Glacier.
- To speed up data transfer: Perform multiple write operations at one time, transfer small files in batches, write from multiple sources, dont perform other operations on files during transfer(rename, metadata changes etc), reduce the local network use, eliminate unnecessary hops.
- Typically, files that are 1 MB or smaller should be included in batches. There’s no hard limit on the number of files you can have in a batch, though AWS recommends that you limit your batches to about 10,000 files. Having more than 100,000 files in a batch can affect how quickly those files import into Amazon S3 after you return the device. AWS recommends that the total size of each batch be no larger than 100 GB. Batching files is a manual process, which you have to manage.
Snowmobile
- ~100 PB
- For large datasets of 10PB or more in a single location.
- Supports loading to S3 or Glacier.
S3 Transfer acceleration
- First files transfered to the closest edge location and then routed inside the AWS network.
- With S3TA, you pay only for transfers that are accelerated.
- Upload to a centralized bucket from all over the world.
- Transfer gigabytes to terabytes of data on a regular basis across continents.
- After Transfer Acceleration is enabled, it can take up to 20 minutes for you to realize the performance benefit.
Transfer Family
- Transfer Family provides fully managed(serverless) support for file transfers directly into and out of Amazon S3 or Amazon EFS.
- Support for Secure File Transfer Protocol (SFTP), File Transfer Protocol over SSL (FTPS), and File Transfer Protocol (FTP).
VM Import/Export
- CLI command →
aws ec2 create-instance-export-task
Data Transfer
- No charge for inbound data transfer across all services in all Regions.
- Data transfer from AWS to the internet is charged per service, with rates specific to the originating Region.
- There is a charge for data transfer across Regions.
- Data transfer within the same Availability Zone is free.
- Data transfer over a VPC peering connection that stays within an Availability Zone is free. Data transfer over a VPC peering connection that crosses Availability Zones will incur a data transfer charge for ingress/egress traffic. If the VPCs are peered across Regions, standard inter-Region data transfer charges will apply.
- Data processing charges apply for each GB sent from a VPC, Direct Connect, or VPN to Transit Gateway.
- Direct Connect and VPN also incur charges for data flowing out of AWS.
For choosing between data transfer options:
- The AWS Snow Family is a better choice for moving large batches of data at once.
- Direct Connect is a better choice for a private networking requirement.
- AWS VPN is a better choice if you want to add encryption in transit.
Encryption
- Encryption in transit → VPN with IPSec, TLS for network level traffic, SSL certs for web apps and CloudFront, HTTPS listeners for LBs, SSL to encrypt connection to DB instance, VPC endpoints to keep data transit inside AWS.
- Encryption at rest → AES256 AWS standard option, client side option, KMS.
KMS
- Highly available, durable, fully managed service that lets you create, manage, and control cryptographic keys across your applications and more than 100 AWS services.
- Centralized control over the lifecycle and permissions of your keys.
- You can import keys from your own key management infrastructure(256-bit symmetric keys.)
- Create and use asymmetric KMS keys and data key pairs.
- Customer Master Keys(CMKs) includes metadata(key id, creation date, etc), encrypt and decrypt up to 4KB of data. Generate, encrypt, decrypt the data keys used outside of KMS to encrypt data(envelope encryption). Normally used to generate data keys that are then used to encrypt/decrypt data (KEY→ view:yes, manage:yes, used only for my account:yes)
- AWS managed CMK
(KEY→ view:yes, manage:no, used only for my account:yes) - AWS owned CMK
(KEY→ view:no, manage:no, used only for my account:no) - Data keys: encryption keys used to encrypt data, encrypted with CMK, KMS doesn’t track data keys, data keys need to be managed by customer.
- Key policies and grants to manage access.
GenerateDataKey→ returns plaintext and encrypted data key under the CMK. Remove the plaintext data key after data has been ecnrypted. You can store the encrypted data key along with the encrypted data to later decrypt the data.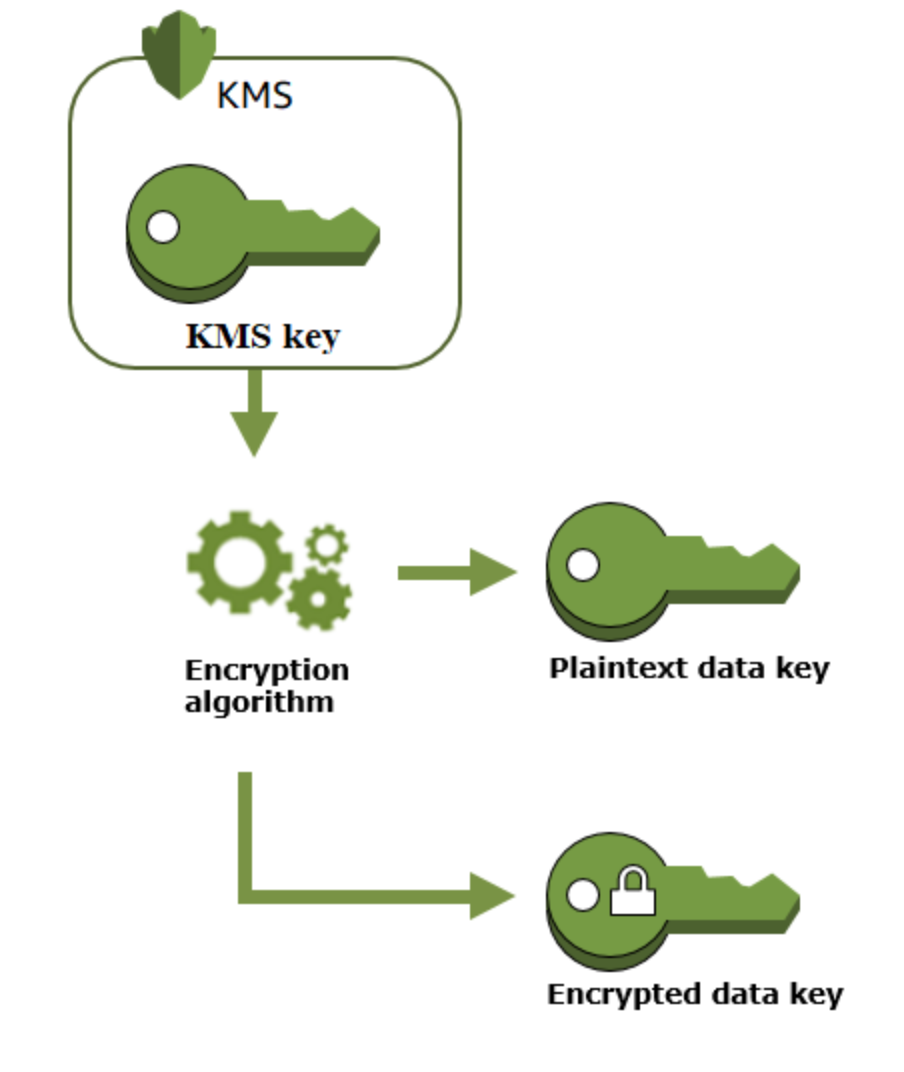
- If you choose to have AWS KMS automatically rotate keys, you don’t have to re- encrypt your data. AWS KMS automatically keeps previous versions of keys to use for decryption of data encrypted under an old version of a key. All new encryption requests against a key in AWS KMS are encrypted under the newest version of the key.
- Schedule key deletion with configurable waiting period from 7 to 30 days.
- Up to 100,000 KMS keys per account per Region.
- Key policies don’t automatically give permission to the account or any of its users. For example, suppose you create a key policy that gives only one user access to the KMS key. If you then delete that user, the key becomes unmanageable and you must contact AWS Support to regain access to the KMS key.
- SSE-S3 requires that Amazon S3 manage the data and the encryption keys.
- SSE-C requires that you manage the encryption key.
- SSE-KMS requires that AWS manage the data key but you manage the customer master key (CMK) in AWS KMS.
- Pricing per key and per api request above the free tier.
Security
ACM
- Can import your own certificates.
- ACM certificates must be in the same Region as the resource where they are being used. The only exception is Amazon CloudFront, a global service that requires certificates in the US East (N. Virginia) region. ACM certificates in this region that are associated with a CloudFront distribution are distributed to all the geographic locations configured for that distribution.
- Default 13 months validity.
- Each cert should have at least one fully qualified domain.
- Helps you comply with regulatory requirements by making it easy to facilitate secure connections, a common requirement across many compliance programs such as PCI, FedRAMP, and HIPAA.
- Server Name Indication (SNI) custom SSL → for multiple domains to serve SSL traffic over the same IP address.
GuardDuty
- One-click deployment with no additional software or infrastructure to deploy and manage. By default regional resource.
- Continuous intelligent threat detection and security monitoring, VPC flow logs, DNS Logs, CloudTrail event logs, EKS, RDS. Uses existing threat intelligence feeds and lists that contain malicious IPs, domains. ML, behavioral modeling to catch
anomalous behaviors, AuroraDB and S3.
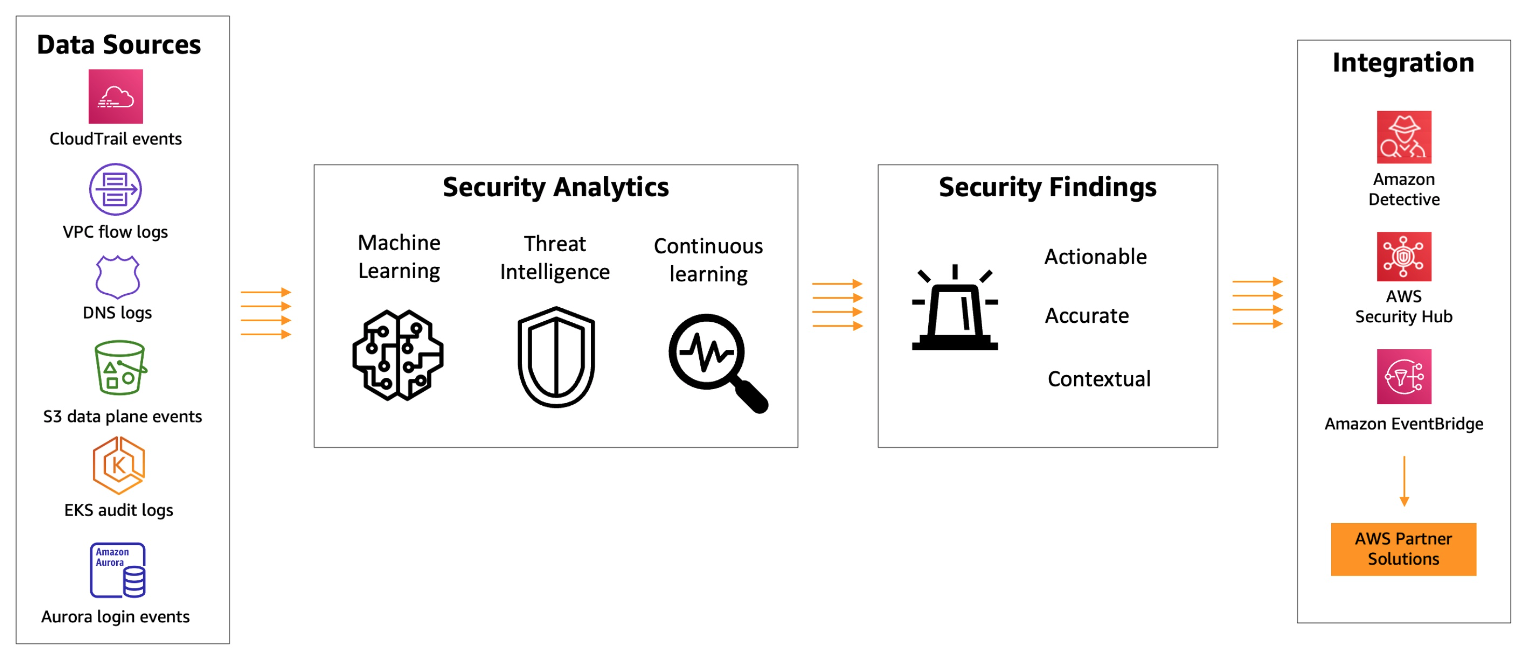
- Can detect: escalation privileges, exposed credentials, communication with malicious external systems, detect compromised ec2 with malware, detect unauthorized infra deployments, reconnaissance, account compromise.
- Invite other accounts to use and become master account → Then you can get findings of member accounts.
- Integrates with Security Hub, Detective.
- Automated remediation possible with API, cli, EventBridge + Lambda.
- Aggregate security findings produced by GuardDuty across Regions using Amazon CloudWatch Events or pushing findings to your data store (like S3) and then aggregating findings as you see fit. You can also send GuardDuty findings to AWS Security Hub and use its cross-Region aggregation capability.
- Associate and manage multiple AWS accounts from a single administrator account. GuardDuty is integrated with AWS Organizations, allowing you to delegate an administrator account for GuardDuty for your organization.This delegated administrator (DA) account is a centralized account that consolidates all findings and can configure all member accounts.
- Pricing per log events and GB processed.
Shield
-
Protect against DDo,S, SYN floods, UDP floods, or other reflection attacks.
-
Shield standard automatically available without extra charge.
-
Shield advanced → higher lvl protection against larger attacks, 24/7 access to DDoS response team, advanced real time metrics and reports and threat intelligence dashboard.
-
Shield standard is free. Shield advanced ~3k + data transfer out.
-
DDoS mitigation without Shield Advanced: a) Use CloudFront b) Add CloudWatch alerts for CPU, NetworkIn c) Set up autoscaling behind ELB d) Integrate WAF with ALB
Web Application Firewall(WAF)
- Protect against common web based attacks and exploits.
- Security rules that control bot traffic and block common attack patterns such as SQL injection or cross-site scripting (XSS).
- Tightly integrates with CloudFront and ALB, API Gateway, and AWS AppSync. AWS WAF rules cannot protect a Network Load Balancer.
- Can create rules that can block or rate-limit traffic from specific user-agents, from specific IP addresses, or that contain particular request headers.
- Can leverage rate-based rules to limit access to certain parts of a webpage(e.g. login page).
- Pricing is per ACL, per rule, per request.
Firewall Manager
- Centrally configure and manage firewall rules across your accounts and applications in AWS Organizations.
- You can centrally configure AWS WAF rules, AWS Shield Advanced protection, Amazon Virtual Private Cloud (VPC) security groups, AWS Network Firewalls, and Amazon Route 53 Resolver DNS Firewall rules across accounts and resources in your organization. It does not support Network ACLs as of today.
AWS Network Firewall
- With Network Firewall, you can filter traffic at the perimeter of your VPC. This includes filtering traffic going to and coming from an internet gateway, NAT gateway, or over VPN or AWS Direct Connect
AWS Config
- Configuration history and changes on AWS resources or software(OS and system- level configuration changes with Systems manager integration).
- Discovers, maps, and tracks AWS resource relationships in your account.
- Pre-built or custom rules (on AWS Lambda) evaluating the configurations of your cloud resources.
- Conformance packs are collection of rules + remediation actions into a single entity and deploy it across an Organization. Common baseline for resource configuration policies and best practices across multiple accounts. Conformance packs also provide compliance scores.
- Multi-account, multi-Region data aggregation for centralized auditing and governance using an aggregator resource. Associate your AWS Organization to quickly add your accounts. The aggregated dashboard on AWS Config will display the total count of non-compliant rules across your Organization.
- Supports extensibility → publish the configuration of third-party resources into AWS Config using our public API operations(e.g. GitHub, Microsoft AD, on premises server).
- Visual dashboard to help you quickly spot non-compliant resources and take appropriate action.
- Partners who provide solutions that integrate with AWS Config for resource discovery, change management, compliance, or security.
- Connect with ITSM / ITOM Software(Jira Service Desk, ServiceNow).
- AWS Config applies remediation using AWS Systems Manager Automation documents.
- Pricing is per config item, per rule, per conformance pack
Security Hub
- Gives you an overview of security and compliance status of your AWS account(s) that performs security best practice checks, aggregates alerts, and enables automated remediation.
- Collects and consolidates GuardDuty, Config, Inspector, Macie, WAF, partner solutions.
- Integrate security findings from AWS services and third-party products.
- With finding aggregation you can use a single region to view and update findings from multiple linked regions and accounts.
- AWS Security Hub creates a score to show you how you are doing against security standards and displays it on the main AWS Security Hub dashboard.
- Custom actions for remediation with EventBridge, Lambda or Systems Manager.
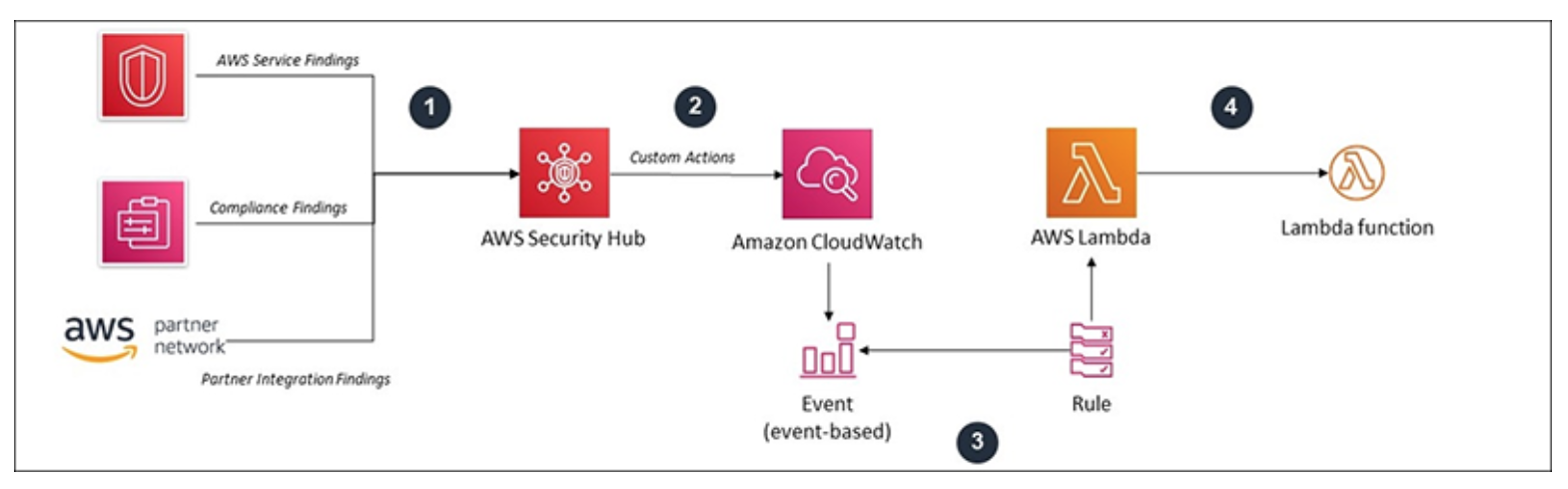
- If a compliance standard, such as PCI-DSS, is already present in AWS Security Hub, then the fully managed AWS Security Hub service is the easiest way to operationalize it.
AWS Secrets Manager
- Centrally manage lifecycle of secrets.
- Automatic secrets rotation without disrupting applications.
- Automatic replication of secrets to multiple AWS Regions.
- Config Rules to help you verify that your secrets are configured in accordance with your organization’s security and compliance requirements.
- AWS Secrets Manager uses envelope encryption (AES-256 encryption algorithm) to encrypt your secrets in AWS Key Management Service (KMS).
- To rotate the keys successfully you need to configure an Amazon VPC interface endpoint to access AWS services running in Amazon VPC private subnets because these subnets don’t have internet access. Pricing is per secret stored and per api call.
Inspector
- Automated vulnerability management service. Automatically discovers all Amazon EC2 instances, Lambda functions, and container images residing in Amazon ECR that are identified for scanning, and then immediately starts scanning them for software vulnerabilities and unintended network exposure.
- Scans EC2, ECR registry for vulnerabilities and unintended network exposure.
- Simplified one-click onboarding and integration with AWS Organizations by setting a Delegated Administrator (DA) account.
- All findings are aggregated in the Amazon Inspector console, routed to AWS Security Hub, and pushed through Amazon EventBridge to automate workflows such as ticketing.
- Vulnerabilities detected in software dependencies used in AWS Lambda functions are automatically mapped to the underlying Lambda layers, making remediation efforts easier.
- You can generate reports in multiple formats (CSV or JSON) with a few clicks in the Amazon Inspector console or through the Amazon Inspector APIs.
- Integrates with partners for extensibility. Pricing is per ec2 scanned, per container image scanned, per lambda scanned.
Licence Manager
- Allows to define rules for licences and Integrates with EC2 to enforce licensing rules and track usage.
CloudTrail
- Auditing, security monitoring, operational troubleshooting → records all API calls.
- Management events and Data events(S3 operations).
- Event history(90 days of control plane actions at no additional cost).
- CloudTrail Lake → managed data lake for capturing, storing, accessing, analyzing user and API activity for audit and security purposes for up to seven years and query logs within seconds for search and analysis. run SQL-based queries on activity logs for auditing within the lake.
- You can deliver your ongoing management and data events to S3 and optionally to CloudWatch Logs or EventBridge by creating trails. Trails capture a record of AWS account activities. Up to 5 trails per region.
- Enable CloudTrail Insights in your trails to identify unusual operational activity in your AWS accounts. e.g. misbehaving scripts or apps → bursts in IAM calls.
- Log file integrity validation feature to see if logs have been tampered.
- Possible to capture and store events from muliple regions and multiple accounts in a single location.
- Turning on CloudTrail has no impact on performance for your AWS resources or API call latency.
- To detect the presence of public S3 objects → CloudTrail, s3 object-logging, EventBridge.
- For global services such as AWS Identity and Access Management (IAM), AWS STS, Amazon CloudFront, and Route 53, events are delivered to any trail that includes global services (IncludeGlobalServiceEvents flag).
- For multi-region trails enables the flag —is-multi-region-trail
- To create an organization trail for all AWS accounts, ensure that the
Enable for all accounts in my organizationoption is checked when you create a new CloudTrail trail. Pricing is per lake (ingestion and storage per GB), per trail( data & management events), and per insight (events analyzed).
DNS
Route53
- Highly available and scalable DNS web service.
- Your DNS records are organized into “hosted zones” that you configure with Route 53’s API.
- You can transfer an external domain to Route53 so that you can conveniently manage your domain names and DNS configuration in a single location.
- To keep your domain name with the current registrar, inform the registrar to update the name servers for your domain to the ones associated with your hosted zone.
- With query logging, Amazon Route 53 sends logs to CloudWatch Logs.
- Route53 uses anycast to help end users’ DNS queries get answered from the optimal Route 53 location.
- Maximum of 500 hosted zones and 10,000 resource record sets per hosted zone.
- Possible to create multiple hosted zones for the same domain name for testing purposes.
- Alias records, which are an Amazon Route 53-specific extension to DNS and let you route traffic to AWS resources, are free. To route domain traffic to an ELB load balancer, use Amazon Route 53 to create an alias record that points to your load balancer. It’s similar to a CNAME record, but you can create an alias record both for the root domain, such as example.com, and for subdomains, such as www.example.com. (You can create CNAME records only for subdomains). a) For EC2 instances, → Type A Record without an Alias b) For ELB, Cloudfront, and S3 → Type A Record with an Alias, c) For RDS → CNAME Record with no Alias.
- Supports both forward (AAAA) and reverse (PTR) IPv6 records.
- Geo DNS lets you balance load by directing requests to specific endpoints based on the geographic location from which the request originates.
- Traffic Flow is an easy-to-use and cost-effective global traffic management service.
- Supports health checks over HTTPS, HTTP or TCP.
- Each health check’s results are published as Amazon CloudWatch metrics showing the endpoint’s health and, optionally, the latency of the endpoint’s response.
- Metric based health checks let you perform DNS failover based on any metric that is available within Amazon CloudWatch, including AWS-provided metrics and custom metrics.
- Resolver is integrated with AWS Resource Access Manager (RAM) which provides
customers with a simple way to share their resources across AWS accounts or within
their AWS Organization.
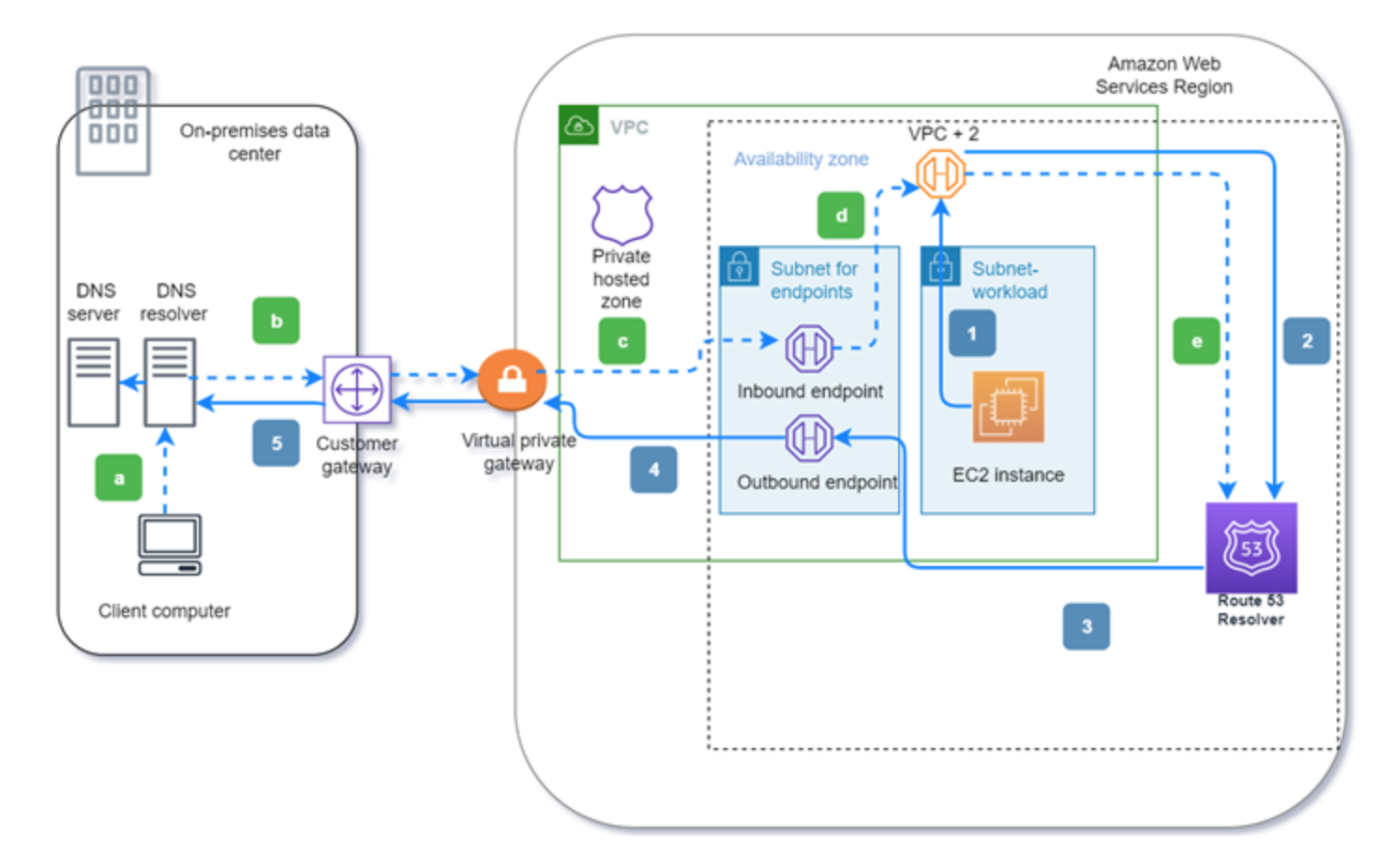
- To resolve any DNS queries for resources in the AWS VPC from the on-premises network, you can create an inbound endpoint on Route 53 Resolver
- To resolve DNS queries for any resources in the on-premises network from the AWS VPC, you can create an outbound endpoint on Route 53 Resolver.
- You can associate a VPC from one account with a private hosted zone in a different account. You first must authorize the association. In addition, you can’t use the AWS console(use AWS CLI) either to authorize the association or associate the VPCs with the hosted zone. Optional but recommended – Delete the authorization to associate the VPC with the hosted zone.
- Allows you to enable Domain Name System Security Extensions (DNSSEC) signing for all existing and new public hosted zones, and enable DNSSEC validation for Amazon Route 53 Resolver. Amazon Route 53 DNSSEC provides data origin authentication and data integrity verification for DNS and can help customers meet compliance mandates, such as FedRAMP. Route 53 cryptographically signs each record in that hosted zone. When you enable DNSSEC validation on the Route 53 Resolver in your VPC, it ensures that DNS responses have not been tampered with in transit. This can prevent DNS Spoofing.
- You can specify multiple values for almost any record, but multivalue answer routing also lets you check the health of each resource, so Route 53 returns only value for healthy resources. It’s not a substitute for a load balancer, but the ability to return multiple health-checkable IP addresses is a way to use DNS to improve availability and load balancing
- Pricing: monthly charge for each hosted zone managed with Route 53, incur charges for every DNS query answered by the Amazon Route 53, annual charge for each domain name registered via or transferred into Route 53.
Storage
S3
- S3 Replication enables automatic, asynchronous copying of objects across Amazon S3 buckets. There are two types of Replications: a) Cross-Region replication (CRR) is used to copy objects across Amazon S3 buckets in different AWS Regions. b) Same-Region replication (SRR) is used to copy objects across Amazon S3 buckets in the same AWS Region.
- For cross region replication, versioning must be enabled in both sources and destination buckets.
- By default, an S3 object is owned by the AWS account that uploaded it. This is
true even when the bucket is owned by another account. To get full access to the
object, the object owner must explicitly grant the bucket owner access. You can create a bucket policy to require external users to grant
bucket-owner-full-controlwhen uploading objects so the bucket owner can have full access to the objects. - You can change the storage class of the replicated items.
- Once you version-enable a bucket, it can never return to an unversioned state. Versioning can only be suspended once it has been enabled.
- Metadata, which can be included with the object, is not encrypted while being stored on Amazon S3. Therefore, AWS recommends that customers not place sensitive information in Amazon S3 metadata.
- Object lock: store objects as locked(only on versioned buckets).
- Objects stored in a bucket before enabling versioning have a version ID null.
- You can place a retention period on an object version. Different versions of a single object can have different retention modes and periods.
- To host a static website, you configure an Amazon S3 bucket for website hosting, and then upload your website content to the bucket. This bucket must have public read access. You must give the bucket the same name as the record that you want to use to route traffic to the bucket.
- S3 static website: a) To allow public read access to objects, the account that owns the bucket must own the objects b) on S3 bucket that allows anonymous or public access will not apply to objects that are encrypted with AWS KMS. You must remove KMS encryption from the objects that you want to serve using the Amazon S3 static website endpoint.
- Up to 24 hours can pass before the bucket name propagates across all AWS Regions. During this time, you might receive the 307 Temporary Redirect response for requests to Regional endpoints that aren’t in the same Region as your bucket.
- Amazon S3 server access logging captures all bucket-level and object-level events.
- Using the Range HTTP header in a GET Object request, you can fetch a byte-range from an object, transferring only the specified portion. A byte-range request is a perfect way to get the beginning/end of a file and ensuring we remain efficient during our scan of our S3 bucket.
- With Amazon S3 Select, you can scan a subset of an object by specifying a range of bytes to query using the ScanRange parameter.
- Max object upload 5GB. When your object size reaches 100 MB, you should consider using multipart uploads. Upload a single object as a set of parts. You can upload these object parts independently and in any order. If transmission of any part fails, you can retransmit that part without affecting other parts.
- Max object size 5TB.
- Use S3 Access Points to manage access to shared datasets on Amazon S3. VPC Gateway endpoint + S3 access endpoint + bucket policy.
- S3 standard IA, one-zone IA, intelligent tier has a minimum storage duration charge of 30 days.
- S3 Glacier has a minimum storage duration charge of 90 days.
- S3 Glacier deep archive has a minimum storage duration charge of 180 days.
- S3 Standard no minimum storage duration
- The AWS S3 sync command uses the
CopyObjectAPIs to copy objects between S3 buckets. - You can increase your read or write performance by parallelizing reads with prefixes.
- To encrypt an object at the time of upload, you need to add a header
called
x-amz-server-side-encryption. To enforce object encryption, create an S3 bucket policy that denies any S3 Put request that does not include thex-amz-server-side-encryptionheader. - When you use server-side encryption with Amazon S3 managed keys (SSE-S3), each object is encrypted with a unique key. As an additional safeguard, it encrypts the key itself with a root key that it regularly rotates.
- Amazon S3 now applies server-side encryption with Amazon S3 managed keys (SSE- S3) as the base level of encryption for every bucket in Amazon S3.
- Bucket owners pay for all Amazon S3 storage and data transfer costs associated with their bucket. A bucket owner, however, can configure a bucket to be a Requester Pays bucket.
With Requester Paysbuckets, the requester instead of the bucket owner pays the cost of the request and the data download from the bucket. The bucket owner always pays the cost of storing data. You must authenticate all requests involving Requester Pays buckets. Requesters must includex-amz-request-payerin their requests either in the header, for POST, GET and HEAD requests, or as a parameter in a REST request to show that they understand that they will be charged for the request and the data download. - S3 notifications events: New object created, object removal, restore object, reduced redundandcy storage object lost, replication,S3 Lifecycle expiration events, S3 Lifecycle transition events, S3 Intelligent-Tiering automatic archival events, Object tagging events, Object ACL PUT events. Enabling notifications is a bucket-level operation; that is, you store notification configuration information in the notification subresource associated with a bucket. Destinations: SNS, SQS, Lambda, Amazon EventBridge
Glacier
- Vault Lock allows you to easily deploy and enforce compliance controls for individual S3 Glacier vaults with a vault lock policy.
EBS
- Copy snapshots don’t inherit the retention schedule and can be kept indefinitely.
- For an encrypted EBS volume data stored at rest on the volume, data moving between the volume and the instance, snapshots created from the volume, and volumes created from those snapshots are all encrypted.
- Amazon EBS Multi-Attach enables you to attach a single Provisioned IOPS SSD (io1 or io2) volume to multiple instances with Nitro system that are in the same Availability Zone.
- EBS volume are locked to AZ, to attach to other AZ you have to snapshot it.
- Copying an unencrypted snapshot allows encryption.
Instance store
- SSD-based instance store volumes support more than a million IOPS for random reads.
- Cant create snapshots for instance store volumes.
EFS
- POSIX compliant.
- 1000s on concurrent NFS clients, 10Gbs throughput.
- With Amazon EFS, you pay only for the resources that you use.
- Use EFS Access Points to manage application access.
- Higher price point than EBS.
- Maximum days for the EFS lifecycle policy is 90.
- Encryption at rest must be enabled at creation time, Encryption in transit can be enabled during mount time.
- For encryption in transit, there is no need to add custom security group rules for port 443.
- Access controls with endpoints in your Amazon VPC (mount targets) and POSIX- compliant user and group-level permissions.
FSx for Windows
- Multi-az possible, automatically provisions and maintains a standby file server in a different Availability Zone.
- Test the failover of your Multi-AZ file system by modifying its throughput capacity.
- Monitor storage capacity and file system activity using Amazon CloudWatch.
- Destination for publishing user access events by logging these events to CloudWatch Logs or streaming to Kinesis Data Firehose.
- Accessible over the Server Message Block (SMB) protocol.
FSx for Lustre
- High-performance file system.
- FSx for Lustre can only be used with Linux instances.
Databases
DynamoDB
- Global tables are available across regions with low latency. Must first enable streams.
- Can only query on primary key, sort key, or indexes.
- All DynamoDB tables are encrypted. There is no option to enable or disable encryption for new or existing tables. By default, all DynamoDB tables are encrypted under an AWS owned customer master key (CMK), which do not write to CloudTrail logs.
- You can purchase reserved capacity in advance to lower the costs of running your DynamoDB instance. With reserved capacity, you pay a one-time upfront fee and commit to a minimum usage level over a period of time.
- Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes.
- With provisioned capacity, you pay for the provision of read and write capacity units for your DynamoDB tables. With provisioned capacity, you can also use auto- scaling to automatically adjust your table’s capacity based on the specified utilization rate to ensure application performance, and also potentially reduce costs. Probably best for you if you have relatively predictable application traffic, run applications whose traffic is consistent, and ramps up or down gradually
- DynamoDB on-demand you pay per request for the data reads and writes that your application performs on your tables. DynamoDB instantly accommodates your workloads as they ramp up or down. on-demand capacity mode is probably best when you have new tables with unknown workloads, unpredictable application traffic, and also if you only want to pay exactly for what you use
RDS
- Use RDS performance insights to analyze DB load and DB performance. Also can get performance of SQL queries.
- Supports Cross-Region Automated Backups. Manual snapshots and Read Replicas are also supported across multiple Regions.
- Multi-AZ DB → synchronously replicate the data to a standby instance for failover.
- With Read replicas → asynchronously replicate the data uses the engines native replication to update the read replica whenever there is a change to the source DB instance.
- Multi region → asynchronously replicate the data to other regions.
- Multi-AZ → primary and standby upgraded at the same time.
- To leverage reserved instances from another account in the same organization, you have to use instances with the same DB attributes.
- Use weighted record sets to distribute requests across your read replicas. Within a Route 53 hosted zone, create individual record sets for each DNS endpoint associated with your read replicas. Then, give them the same weight, and direct requests to the endpoint of the record set.
- Amazon RDS does not support certain features in Oracle such as Multitenant Database, Real Application Clusters (RAC), Unified Auditing, Database Vault, and many more.
AuroraDB
- Fully managed postgresql, mysql designed for high performance, availability and global scale.
- Automatic backups and point-in-time restore, storage autoscaling (of 10 GB up to a maximum of 128 TB), multi region replication.
- Up to 15 replicas, automatic failover in case of issues. If no replicas, will attempt to create a new Amazon Aurora DB instance for you automatically.
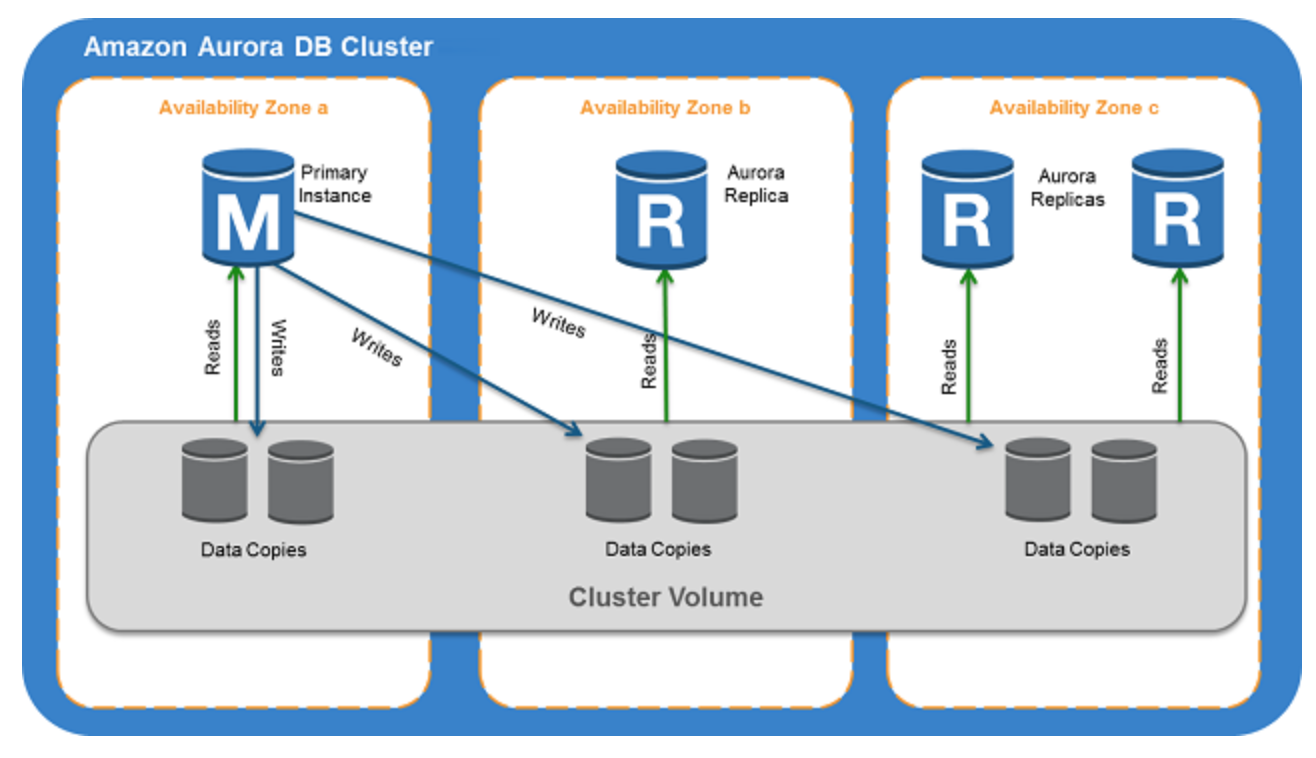
- Global tables for globally distributed applications. storage-based replication to replicate a database across multiple AWS Regions, with typical latency of less than one second. You can use a secondary region as a backup option in case you need to recover quickly from a regional degradation or outage. An Aurora cluster can recover in less than 1 minute even in the event of a complete regional outage This provides your application with an effective Recovery Point Objective (RPO) of 1 second and a Recovery Time Objective (RTO) of less than 1 minute
- Serverless option → where the database automatically starts up, shuts down, and scales capacity up or down based on your application’s needs. Good option if there isn’t consistent load on the DB.
- Aurora parallel query provides faster analytical queries.
- Diagnose and Resolve Performance Bottlenecks with Amazon DevOps Guru for RDS.
- Backtrack for Aurora MySQL without needing to restore data from a backup.
- Aurora is integrated with Amazon GuardDuty to help you identify potential threats to data stored in Aurora databases.
- Amazon RDS Blue/Green Deployments allow you to make safer, simpler, and faster database updates with zero data loss.
- Publish general, slow, audit, and error log data to a log group in Amazon CloudWatch Logs.
- Instrument your SQL database queries by adding the X-Ray SDK.
- Aurora Auto Scaling dynamically adjusts the number of Aurora Replicas.
- You can specify the failover priority for Aurora Replicas, each Read Replica is associated with a priority tier (0-15). Aurora will promote the Read Replica that has the highest priority (the lowest numbered tier). If two or more Aurora Replicas share the same priority, then Amazon RDS promotes the replica that is the largest in size.
DocumentDB
- Interface or gateway endpoints not supported currently.
- DocumentDB Global Clusters: one primary region and up to five read-only secondary regions. You issue write operations directly to the primary cluster in the primary region and Amazon DocumentDB automatically replicates the data to the secondary regions using dedicated infrastructure. Latency is typically under a second.
Elasticache
- For caching, which accelerates application and database performance.
- Simple object caching → Memcached.
- Complex data types(e.g. lists, hashes, bit arrays) → Redis.
- Sorting and ranking of datasets(leaderboards) → Redis.
- For HA, multi-az, failover → Redis.
- Encryption, compliance(e.g. PCI) → Redis.
- Global Datastore in Amazon ElastiCache for Redis provides fully managed, fast, reliable and secure cross-region replication.
- Amazon ElastiCache for Redis provides fully managed, automatic scaling to maintain steady performance for your application demands.
- Redis authentication tokens enable Redis to require a token (password) before allowing clients to run commands.
- You can use both in-transit as well as at-rest encryption to guard against unauthorized access of your data on the server.
AWS Backup
- With continuous backups, you can restore your AWS Backup-supported resource by rewinding it back to a specific time that you choose within 1 second of precision (going back a maximum of 35 days). Continuous backup works by first creating a full backup of your resource and then constantly backing up your resource’s transaction logs.
Data Analytics
Redshift
- Using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables.
- For DR purposes, you can configure Amazon Redshift to automatically copy snapshots for the cluster to another AWS Region.
- To copy snapshots for AWS KMS–encrypted clusters to another AWS Region, you need to create a grant for Redshift to use a KMS customer master key (CMK) in the destination AWS Region.
- Pattern: Kinesis Data Firehose → S3 → RedShift COPY cmd → Redshift.
- For backups, no extra backup storage costs for up to 100% of your provisioned storage. Therefore, if we have a backup policy with 1-day retention we dont have any extra costs.
- Suitable for OLAP scenarios.
- You can migrate data to Amazon Redshift databases using AWS Database Migration Service.
EMR
- Managed platform for big data frameworks(hadoop, spark).
- Vast amount of data, business intelligence workloads.
- EMR cluster: Master node: A node that manages the cluster by running software components to coordinate the distribution of data and tasks among other nodes for processing. Core node: A node with software components that run tasks and store data in the Hadoop Distributed File System (HDFS) on your cluster. Task node: A node with software components that only runs tasks and does not store data in HDFS. Task nodes are optional.
Glue
- Build ETL, fully managed service.
- Glue Data Catalog → central metadata repository.
- ETL engine to generate python or scala code.
Kinesis Data Analytics (KDA)
- Transform and analyze streaming service in real time used with Apache Flink.
- You cannot directly write the output of the records from a Lambda function to KDA.
- Used to build SQL queries on streaming data.
- Sources: Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), servers, IoT, and more.
- Consumers: Kinesis Data Firehose and Lambda.
Kinesis Data Firehose
- Automatically scales to match the throughput of your data and requires no ongoing administration. Auto-scaling solution, as there is no need to provision any shards like Kinesis Data Streams.
- You can configure Amazon Kinesis Data Firehose to aggregate and collate CloudWatch Logs from different AWS accounts and receive their log events in a centralized logging AWS Account by using a CloudWatch Logs destination and then creating a Subscription Filter.
- When a Kinesis data stream is configured as the source of a Firehose delivery stream, Firehose’s PutRecord and PutRecordBatch operations are disabled and Kinesis Agent cannot write to Firehose delivery stream directly. Data needs to be added to the Kinesis data stream through the Kinesis Data Streams PutRecord and PutRecords operations instead.
- Sources: Servers, IoT, and any data source that can call the Kinesis API to send the data.
- Consumers: Amazon Redshift, Amazon OpenSearch Service, Amazon S3, HTTP endpoints, and more.
Kinesis Data Streams
- Facilitate multiple applications consume the same streaming data concurrently and independently. Enables real-time processing of streaming big data, as well as the ability to read and/or replay records in the same order to multiple Amazon Kinesis Applications.
- By default, the 2MB/second/shard output is shared between all of the applications consuming data from the stream. use enhanced fan-out if you have multiple consumers retrieving data from a stream in parallel. Consumers receive their own 2MB/second pipe of read throughput per shard.
- Default data retention 1 day, can go up to 7.
- Sources: Servers, IoT, and any data source that can call the Kinesis API to send the data.
- Consumers: Kinesis Data Analytics, Amazon EC2, Amazon EMR, and AWS Lambda.
Kinesis Video Streams
- Use to stream live video from devices to the AWS Cloud, or build applications for real-time video processing or batch-oriented video analytics.
- Use HLS for live playback. Use the
GetHLSStreamingSessionURLAPI to retrieve the session URL and provide it to your player.
AppStream
- Fully managed service which can be configured for application streaming or for delivery of virtual desktops with selective persistence.
- Empower remote workers to react quickly to changing conditions.
- Monthly fee per streaming user.
AI/ML
Amazon Rekognition
- Deep learning, image recognition service, detect objects within an image.
- Pattern: Recognize something in videos: a) Kinesis video stream for sending
streaming video to Rekognition Video using kinesis
PutMediaAPI b) Amazon Recognition Video Steam processor to manage the analysis c) Kinesis data streams consumer to read the analysis results(e.g. ec2 on asg). - Supports the
IndexFacesoperation. You can use this operation to detect faces in an image and persist information about facial features that are detected in a collection. This is an example of a storage-based API operation because the service persists information on the server.
Amazon Comprehend
- Get insights about the content of docs.
- Detect key phrases, language, sentiment, entities in text, intelligent document processing use cases.
- Search social feeds for mentions.
Amazon Machine Learning Service
- Cloud-based used by devs to leverage ML.
- Devs can use visualization tools and wizards to create ML models without deep ML knowledge.
Amazon Textract
- ML service that automatically extracts text, handwriting, and data from scanned documents.
- It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
- Process invoices and receipts with the
AnalyzeExpenseAPI. - Process ID documents such as driver’s licenses and passports issued by the U.S Government using the
AnalyzeIDAPI.
Amazon Transcribe
- Convert speech to text. Using Automatic Speech Recognition (ASR) technology, customers can choose to use Amazon Transcribe for a variety of business applications, including transcription of voice-based customer service calls, generation of subtitles on audio/video content, and conduct (text-based) content analysis on audio/video content.
Content Delivery & Global Network
CloudFront
- Price Classes let you reduce your delivery prices by excluding Amazon CloudFront’s more expensive edge locations from your Amazon CloudFront distribution.
- Reduce latency by delivering data through our globally dispersed points of presence.
- Offers traffic encryption and access controls.
- Accepts well-formed connections to prevent many common DDoS attacks like SYN floods and UDP reflection attacks from reaching your origin.
- With Signed URLs and Signed Cookies, Token Authentication is supported to restrict access to only authenticated viewers.
- Supports Server Name Indication (SNI) for custom SSL certificates, along with the ability to take incoming HTTP requests and redirect them to secure HTTPS requests to ensure that clients are always directed to the secure version of your website. If you configure CloudFront to serve HTTPS requests using SNI, CloudFront associates your alternate domain name with an IP address for each edge location. The IP address to your domain name is determined during the SSL/TLS handshake negotiation and isn’t dedicated to your distribution.
- Origin Shield enables a centralized caching layer and optimizes cache hit ratios and collapses requests across regions leading to as few as one origin request per object.
- CloudFront supports multiple origins for backend architecture redundancy.
- Amazon CloudFront is integrated with Amazon CloudWatch, and automatically publishes six operational metrics per distribution.
- Amazon CloudFront uses standard cache control headers you set on your files to identify static and dynamic content.
- Geo Restriction feature lets you specify a list of countries in which your users can access your content. Alternatively, you can specify the countries in which your users cannot access your content.
- You can turn on HTTP/3 for new and existing Amazon CloudFront distributions.
- Field-Level Encryption is a feature of CloudFront that allows you to securely upload user-submitted data such as credit card numbers to your origin servers. The sensitive information provided by your clients is encrypted at the edge closer to the user and remains encrypted throughout your entire application stack, ensuring that only applications that need the data—and have the credentials to decrypt it—are able to do so. To use field-level encryption, you configure your CloudFront distribution to specify the set of fields in POST requests that you want to be encrypted, and the public key to use to encrypt them. You can encrypt up to 10 data fields in a request.
- CloudFront by default do not forward query strings, cookies, and many of request headers. You can configure CloudFront to forward selected headers, cookies, and query strings.
- Possibility to add or modify request headers forwarded to the origin and then accept only these requests from the origin.
- CloudFront Functions is a serverless edge compute feature allowing you to run JavaScript code at CloudFront edge locations for lightweight HTTP(s) transformations and manipulations.
- CloudFront signed cookies → provide access to multiple restricted files.
- CloudFront signed URLs → access to one file.
- To increase your cache hit ratio, you can configure your origin to add a Cache- Control max-age directive to your objects, and specify the longest practical value for max-age. The shorter the cache duration, the more frequently CloudFront forwards another request to your origin to determine whether the object has changed and, if so, to get the latest version.
- To improve the cache hit ratio when CloudFront is configured to cache based on request headers, forward and cache based on only specified headers. Remove Authorization HTTP header from the whitelist headers section for cache behavior configured for static content. In addition, AWS recommends not to configure caching based on values in the Date and User-Agent headers
- Lambda@Edge is an extension of AWS Lambda allowing you to run code at global
edge locations without provisioning or managing servers. Lambda@Edge offers
powerful and flexible serverless computing for complex functions and full
application logic closer to your viewers.

- You cannot directly integrate Cognito User Pools with CloudFront distribution as you have to create aseparate Lambda@Edge function to accomplish the authentication via Cognito User Pools.
- lambda@edge lets you execute functions that customize the content that CloudFront delivers. A Lambda function can inspect cookies and rewrite URLs so that users see different versions of a site for A/B testing. Return different objects to viewers based on the device they are using by checking the User-Agent header. Make network calls to external resources to confirm user credentials, or fetch additional content to customize a response.
Global Accelerator(GA)
- Directs traffic to optimal endpoints over the AWS global network.
- Two static anycast IP addresses that act as a fixed entry point to your application endpoints
- Good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP.
- AWS Global Accelerator has the following types of endpoints only - Network Load Balancers, Application Load Balancers, Amazon EC2 instances, or Elastic IP addresses (not possible to front CloudFront distribution)
- Shift traffic gradually or all at once between the blue and the green environment and vice-versa without being subject to DNS caching on client devices and internet resolvers.
- With a custom routing accelerator, you can map one or more users to a specific destination among many destinations. Custom routing accelerators only support virtual private cloud (VPC) subnet endpoint types and route traffic to private IP addresses in that subnet.
CloudFront vs GA
- CloudFront uses multiple sets of dynamically changing IP addresses, pricing is mainly based on data transfer out and HTTP requests, uses edge locations to cache content, and is designed to handle HTTP protocol.
- Global Accelerator provides a set of static IP addresses as a fixed entry point to your applications, charges a fixed hourly fee and an incremental charge over your standard data transfer rates, uses edge locations to find an optimal pathway to the nearest regional endpoint, and is best with both HTTP and non-HTTP protocols, such as TCP and UDP.
Compute
EC2
- Dedicated (Instances) → no other customers share the hardware, May share hardware with instances in YOUR account only.
- (Dedicated) Hosts → book an entire physical server and have full control of EC2 instance placement.
- When you create a launch configuration, the default value for the instance placement tenancy is null and the instance tenancy is controlled by the tenancy attribute of the VPC.
- Good EC2 combo → reserved instances for baseline + on-demand & spot for peaks.
- You can only change the tenancy of an instance from dedicated to host, or from host to dedicated after you’ve launched it.
- EC2 Fleet lets you provision compute capacity across different instance types, Availability Zones and across On-Demand, Reserved Instances (RI) and Spot Instances.
- On-Demand Capacity Reservation → create and manage reserved capacity on Amazon EC2. Define Availability Zone and quantity (number of instances) along with other instance specifications such as instance type and tenancy.
- Userdata executed as root by default.
Hibernate
- Save contents from RAM to EBS root volume. When instance starts, EBS root volume is restored to its previous state and RAM contents are reloaded.
- To use hibernation, the root volume must be an encrypted EBS volume.
- When the instance state is stopping, you will not be billed if it is preparing to stop however, you will still be billed if it is just preparing to hibernate.
Spot
- EC2 fleet won’t automatically failover to on-demand if ec2 spot capacity is not fully fullfilled.
- You pay the Spot price that’s in effect at the beginning of each instance-hour for your running instance. If Spot price changes after you launch the instance, the new price is charged against the instance usage for the subsequent hour.
- Recommend using multiple Spot capacity pools to maximize the amount of Spot capacity available to you.
- Spot blocks are designed not to be interrupted and will run continuously for the duration you select, independent of Spot market price. In rare situations, Spot blocks may be interrupted due to AWS capacity needs.
- Do not support multi-region Fleet requests.
Placement Groups
- It is recommended that you launch the number of instances that you need in the placement group in a single launch request and that you use the same instance type for all instances in the placement group. If you try to add more instances to the placement group later, or if you try to launch more than one instance type in the placement group, you increase your chances of getting an insufficient capacity error.
- If you receive a capacity error when launching an instance in a placement group that already has running instances, stop and start all of the instances in the placement group, and try the launch again. Restarting the instances may migrate them to hardware that has the capacity for all the requested instances.
- Before you move or remove the instance from a placement group, the instance must be in the stopped state. You can move or remove an instance using the AWS CLI or an AWS SDK.
Spread
- Maximum of 7 running instances per Availability Zone per group.
- Recommended for applications that have a small number of critical instances that should be kept separate from each other.
- Spread placement groups provide access to distinct racks, and are therefore suitable for mixing instance types or launching instances over time.
Cluster
- Higher per-flow throughput limit of up to 10 Gbps for TCP/IP traffic and are placed in the same high-bisection bandwidth segment of the network.
Partition
- Spreads your instances across logical partitions such that groups of instances in one partition do not share the underlying hardware with groups of instances in different partitions.
- Used by large distributed and replicated workloads.
EC2 On-demand instance limits
- Amazon EC2 is transitioning On-Demand Instance limits from the current instance count-based limits to the new vCPU-based limits to simplify the limit management experience for AWS customers.
EC2 Image Builder
- Use RAM to share EC2 Image Builder resources, add the shared components, images, recipes in resource shares and configure principals which are allowed to access the shared resources.
- Possible to distribute the AMI to multiple regions or shared with other accounts.
Graviton2
- 40% better price/performance at 20% lower cost over comparable Intel x86.
Graviton3
- 25% better price/performance compared to graviton2.
AWS Batch
- Dynamically provisions the optimal quantity and type of compute resources (e.g., CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted.
- No additional charge, only pay for AWS underlying resources you create to store and run your batch jobs.
- Use AWS Batch to accelerate content creation, dynamically scale media packaging, and automate asynchronous media supply chain workflows.
Containers
ECS
- Fully-managed container orchestration service, with AWS configuration and operational best practices built-in, and no control plane, nodes, or add-ons for you to manage.
- ECS Service Connect simplifies building and operating resilient distributed applications and provides rich traffic telemetry in the ECS console and in Amazon CloudWatch. Supports automatic connection draining that helps your client applications switch to a new version of the service endpoint without encountering traffic errors.
- Serverless by default with built in Fargate.
- Natively integrates with the Security, Identity, and Management and Governance tools.
- Blue/green deployments with AWS CodeDeploy help you minimize downtime during application updates. New version of ECS service alongside the old one and test before rerouting traffic with rapid rollback if necessary.
- Capacity Providers → running a service in a predefined split percentage across Fargate and Fargate Spot.
- Task scheduling for batch jobs.
- Service → specified number of tasks are constantly running and restarts tasks if failure occurs.
- Customize how tasks are placed onto a cluster of Amazon EC2 instances based on built-in attributes such as instance type, Availability Zone, or user-defined custom attributes.
- Autoscaling by integrating Amazon ECS on Fargate with Amazon CloudWatch alarms and Application Auto Scaling.
- ECS on ec2 cluster autoscaling → ASG, capacity provider, CloudWatch, scaling policy.
- ECS on ec2 service autoscaling → Cloudwatch alarms, Application Auto Scaling, scaling policy.
- The scaling policies support a cooldown period. This is the number of seconds to wait for a previous scaling activity to take effect.
- Possiblle to scale to zero when there’s no work to be done, set a minimum capacity of 0.
Fargate
- Choose for isolation model and security, and avoid managing ec2. If you need more control of compute, or customization options, or GPU for ec2 then dont use it.
- Supports graviton2.
- Offers a serverless approach for running your Windows containers.
Elastic Container Registry (ECR)
- Fully managed and highly available container registry.
- Amazon ECR is a Regional service. You can build pipelines to push them to Amazon ECR in one Region, and Amazon ECR can automatically replicate them to other Regions and accounts for deployment to multi-Region clusters.
- OCI and Docker support.
- Tight integration with inspector for vulnerability management.
- Pull through cache repositories help you keep container images sourced from public registries up to date.
- AWS PrivateLink endpoints to allow your instances to pull images from your private repositories without traversing through the public internet.
- You can request a custom alias for images.
- Automatically encrypts images at rest using Amazon S3 server-side encryption or AWS KMS encryption and transfers your container images over HTTPS.
Autoscaling
- Lifecycle hooks enable you to perform custom actions as the Auto Scaling group
launches or terminates instances.
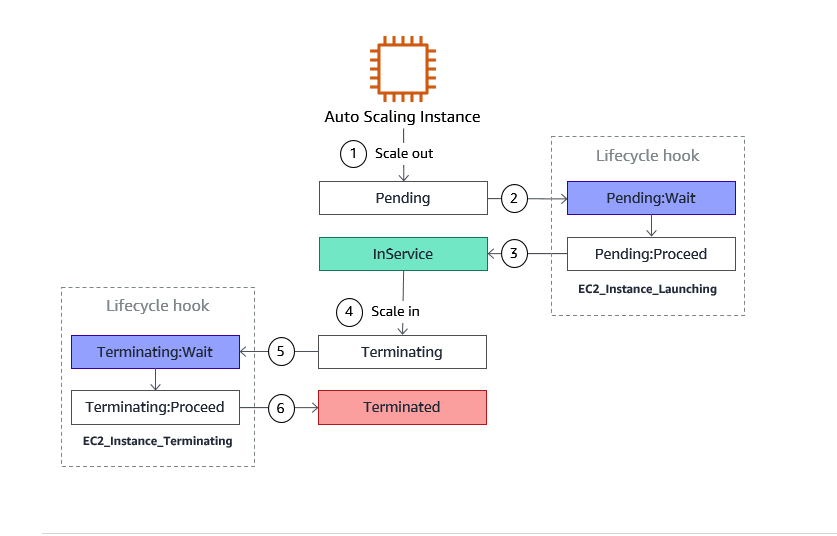
- With launch templates, you can provision capacity across multiple instance types using both On-Demand Instances and Spot Instances.
- Auto Scaling doesn’t terminate an instance that came into service based on EC2 status checks and ELB health checks until the health check grace period expires
- Cooldown period: It ensures that the Auto Scaling group does not launch or terminate additional EC2 instances before the previous scaling activity takes effect(default 300s).
- When there are multiple policies in force at the same time, Auto Scaling chooses the policy that provides the largest capacity for both scale-out and scale-in.
- If you have an EC2 Auto Scaling group (ASG) with running instances and you choose to delete the ASG, the instances will be terminated and the ASG will be deleted.
- Rebalancing AZs launches new instances before terminating the old ones.
- Auto Scaling creates a new scaling activity for terminating the unhealthy instance and then terminates it. Later, another scaling activity launches a new instance to replace the terminated instance.
Loadbalancers
- When cross-zone load balancing is enabled, each load balancer node distributes traffic across the registered targets in all enabled Availability Zones.
- By default, cross-zone load balancing is enabled for Application Load Balancer and disabled for Network Load Balancer.
Classic Load Balancer
- If your application is built within the Amazon Elastic Compute Cloud (Amazon EC2) Classic network.
Gateway Load Balancer
- Deploy and run third-party virtual appliances.
Application Load Balancer
- Operates at the application layer(7) routes to ec2, containers, IP, lambda.
- Advanced loadbalancing http/https based on url, path, method, header, request attributes, source IP, TLS termination.
- Supports sticky sessions(route request to the same target).
- Injects a new custom identifier “X-Amzn-Trace-Id” HTTP header on all requests coming into the load balancer for easier tracking.
- Multiple certificates with SNI. Bind multiple certificates to the same secure listener on your load balancer.
- Seamlessly integrated with Amazon Cognito for user auth and has native support for OpenID Connect (IODC) identity providers (IdPs).
- ALB targets with instance ID route to primary private IP in primary NIC, targets using IP addresses route to any private IP from one or more NICs.
- Cannot directly upload a self-signed certificate in your ALB
- Pricing: per Application Load Balancer-hour, Load Balancer Capacity Units (LCU)(active/new connections, processed bytes, rule evaluations) used per hour.
Network Loadbalancer
- Flow hash routing algorithm can only be used with Network Load Balancers.
- Network LB has no security groups, lets traffic passing by.
- DDos protection: Implement CloudFront and use your Network Load Balancer as the origin. You can also use AWS Shield Advanced.
- NLB is a good choice if you expect millions of requests per second.
Serverless, Events, Queues, Notifications
Lambda
- Serverless Application Model (SAM) is an open source framework for building serverless applications. traffic shifting feature of SAM to easily test the new version of the Lambda function without having to manually move 100% of the traffic to the new version in one shot.
- AWS Lambda currently supports 1000 concurrent executions per AWS account per region. More requests will be throttled.
- Lambda extentions through lambda layers to integrate with other tools.
- Get the max memory used for a function call from CW logs.
- Reserved concurrency – Reserved concurrency creates a pool of requests that can only be used by its function, and also prevents its function from using unreserved concurrency.
- Provisioned concurrency – Provisioned concurrency initializes a requested number of execution environments so that they are prepared to respond to your function’s invocations.
API Gateway
- Per-client throttling limits are applied to clients that use API keys associated with your usage plan as a client identifier. Note that these limits can't be higher than the per-account limits.
- An API call through API Gateway cannot exceed 29 seconds due to the limits and not possible to increase.
- API caching in Amazon API Gateway to cache your endpoint's responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API.
- For websocket APIs, use @connections in your backend service to send a callback message to a connected client, get connection information, or disconnect the client.
- With API Gateway, you can send the stream to an Amazon Kinesis data stream on which you can group requests in batches so there will be a decrease in requests in Lambda.
Step Functions
- Can’t trigger an AWS Step Function directly from an S3 event, need a lambda first. Amazon Mechanical Turk (MTurk) is a crowdsourcing marketplace that makes it easier for individuals and businesses to outsource their processes and jobs to a distributed workforce who can perform these tasks virtually. You can integrate A Amazon Mechanical Turk and SWF to implement a set of workflows for batch processing.
EventBridge
- All state changes events from AWS services are free
- Pay only per custom event, per 3rd part events, and for cross-account events.
SQS
- Use group ID with FIFO queues to help with FIFO delivery.
- FIFO supports 300 transactions (API calls) per second (300 send, receive, or delete operations per second). When you batch 10 transactions per operation (maximum), FIFO queues can support up to 3,000 (30010) transactions per second.
- Message retention 4 days default, 14 days max.
- Message timers to set an initial invisibility period for a message added to a queue. The default (minimum) delay for a message is 0 seconds. The maximum is 15 minutes.
- Use when you need a) messaging semantics(message-level ack/fail), visibility timeout, b) dynamically increasing concurrency/throughput at read time.
- SQS + lambda: For standard queues, Lambda uses long polling to poll a queue until it becomes active. When messages are available, Lambda reads up to five batches and sends them to your function.
- To scale to same number of consumers as producers, send data with a Group ID attribute.
- A single SQS message queue can contain an unlimited number of messages. However, there is a 120,000 quota for the number of inflight messages for a standard queue and 20,000 for a FIFO queue. Messages are inflight after they have been received from the queue by a consuming component, but have not yet been deletedfrom the queue.
- By default, ReceiveMessageWaitTimeSeconds is zero which means it is using Short polling. If it is set to a value greater than zero, then it is Long polling.
- You cant change an existing standard queue to FIFO → delete and recreate.
- Original and dead letter queue types must match.
- You can configure visibility timeout only for specific messages(e.g. with specific headers).
- The maxReceiveCount is the number of times a consumer tries receiving a message from a queue without deleting it before being moved to the dead-letter queue. Setting the maxReceiveCount to a low value, such as 1 would result in any failure to receive a message to cause the message to be moved to the dead-letter queue. Such failures include network errors and client dependency errors.
SNS
- Use SNS message filtering to assign a filter policy to the topic subscription, and the subscriber will only receive a message that they are interested in.
- SNS FIFO for strict message ordering and deduplicated message delivery to one or more subscribers.
- Amazon SNS Mobile Push Notifications, you have the ability to send push notification messages directly to apps on mobile devices. Push notification messages sent to a mobile endpoint can appear in the mobile app as message alerts, badge updates, or even sound alerts.
Amazon PinPoint
- To send push notifications
- offers marketers and developers one customizable tool to deliver customer communications across channels, segments, and campaigns at scale.
CI/CD
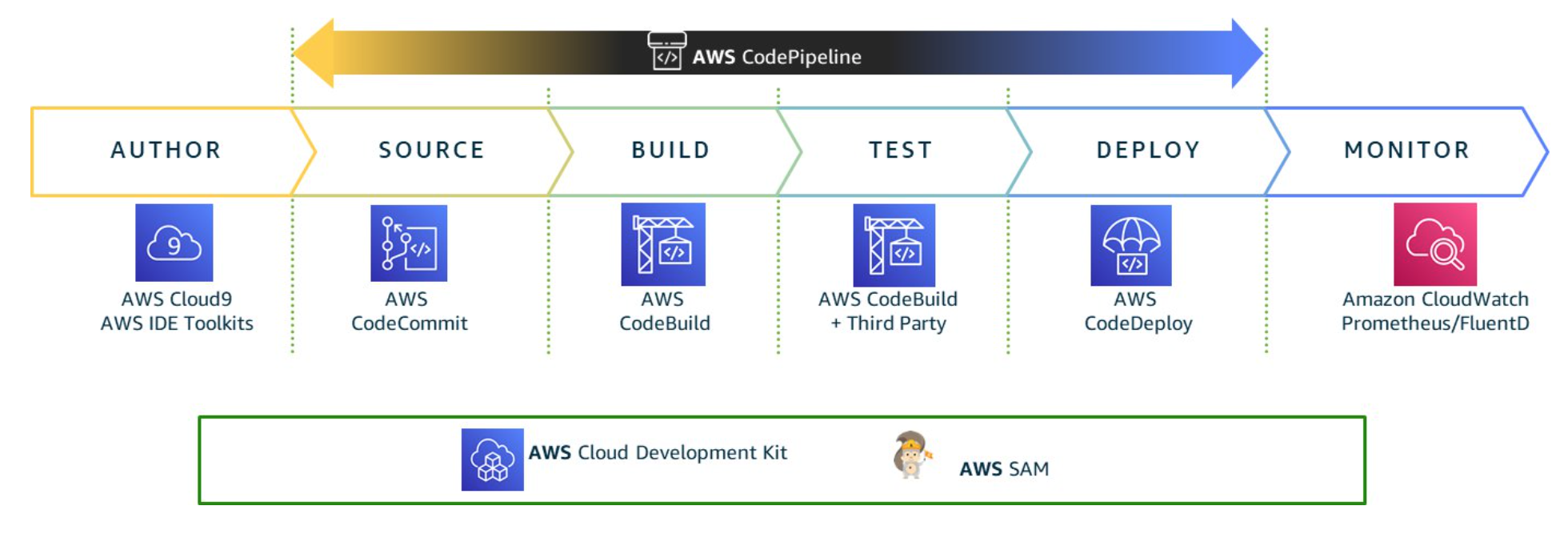
CodeCommit
- Highly scalable, managed source control service for private git repositories.
- Can be used with Git repositories that include submodules.
- A single file in a repository cannot be more than 2 GB in size.
- Deleting an AWS CodeCommit repository is a destructive one-way operation that cannot be undone.
- CodeCommit supports code reviews and enables you to set permissions on branches of your code.
- HTTPS or SSH protocols or both to communicate with AWS CodeCommit.
- Repositories are automatically encrypted at rest.
- Automation use case: Lambda function that will scan the CodeCommit code submissions for IAM credentials, and then send out notifications or perform corrective actions.
CodeBuild
- Fully managed continuous integration service that compiles source code, builds packages, runs tests, and produces ready-to-deploy software packages. With CodeBuild, you don’t need to provision, manage, and scale your own build servers.
- Supports sources GitHub, GitHub Enterprise, Bitbucket, or Amazon S3. CodeCommit.
- CodeBuilld has a Jenkins plugin provides a build step for your Jenkins project to send your build jobs to CodeBuild eliminating the need for provisioning and managing the Jenkins worker nodes.
- CodeBuild runs your build in fresh environments isolated from other users and discards each build environment upon completion. CodeBuild provides security and separation at the infrastructure and execution levels.
CodeDeploy
- Fully managed, automates deployment to ec2, ecs, lambda, and on-premises.
- Protects your application from downtime during deployments through rolling updates and deployment health tracking.
- Supports Rolling and Blue/Green updates.
- Agents that have been tested on Amazon Linux, Red Hat Enterprise Linux, Ubuntu Server, and Microsoft Windows Server.
- CodeDeploy has a Jenkins plugin that provides a post-build step for your Jenkins project. Upon a successful build, it will zip the workspace, upload to S3, and start a new deployment. Supports also other 3rd party integrations.
- CodeDeploy to create a deployment process that publishes the new Lambda version but does not send any traffic to it. Then it executes a PreTraffic test to ensure that your new function works as expected. After the test succeeds, CodeDeploy automatically shifts traffic gradually to the new version of the Lambda function.
CodePipeline
- Fully managed automate continuous delivery pipelines.
- Webhooks, SNS, Slack, Chime, MS Teams for notifications.
- Possibility to register a custom action and own custom systems.
- Pull source code for your pipeline directly from AWS CodeCommit, GitHub, Amazon ECR, or Amazon S3.
- Build and test with CodeBuild.
- Deploy using CodeDeploy, Elastic Beanstalk, ECS, Fargate.
- Trigger custom actions at any point with lambda.
- Allows you to integrate third-party developer tools, like GitHub or Jenkins, into any stage of your release process with one click.
Observability & Monitoring
CloudWatch
- Easily collect and store logs and infra, app, container metrics.
- Build alarms, dashboards.
- Container insights provide automatic dashboards in the CloudWatch console.
- Automate response to operational changes with cloudwatch events.
- CloudWatch log insights → understand, improve, and debug their applications, by allowing them to search and visualize their logs.
- Offers anomaly detection on alarms.
- CloudWatch ServiceLens logs, metrics, traces.
- Cross-account →
Monitoring accountis a central AWS account that can view and interact with observability data generated across other accounts. - Possible to have single dashboard to report metrics from different regions.
Xray
- Complete view of requests as they travel through your distributed apps and different AWS components with end-to-end tracing capabilities. Identify performance bottlenecks and hard to detect issues .
- An X-Ray trace is a set of data points that share the same trace ID.
- An X-Ray segment encapsulates all the data points for a single component (for example, authorization service).
- An X-Ray annotation is system-defined or user-defined data associated with a segment.
- Works with lambda, ecs, ec2, sqs. sns , elastic beanstalk.
- Integrate the X-Ray SDK with your application and install the X-Ray agent. For example for ECS, you will need to install the X-Ray agent and instrument your application code.
- Captures metadata for requests to RDS/Aurora.
- Node.js, Java, and .NET.
- Service Map → creates a map of services used by your application with trace data that you can use to drill into specific services or issues. This provides a view of connections between service.
- AWS X-Ray enables customers to choose their own sampling rate.
- Can use X-Ray to track requests flowing through applications or services across multiple regions and AWS accounts.
- X-Ray stores trace data for the last 30 days. This enables you to query trace data going back 30 days.
- Your Lambda functions send trace data to X-Ray, and X-Ray processes the data to generate a service map and searchable trace summaries.
- Pricing per traces received, retrieved, scanned.
Operations
Systems manager
- Systems Manager supports an SSM document for Patch Manager, AWS-RunPatchBaseline, which performs patching operations on instances for both security-related and other types of updates. When the document is run, it uses the patch baseline currently specified as the "default" for an operating system type.
- The
AWS-ApplyPatchBaselineSSM document supports patching on Windows instances only and doesn’t support Linux instances. For applying patch baselines to both Windows Server and Linux instances, the recommended SSM document isAWS-RunPatchBaseline. - A patch group is an optional means of organizing instances for patching. For example, you can create patch groups for different operating systems (Linux or Windows), different environments (Development, Test, and Production), or different server functions (web servers, file servers, databases).
- State Manager, a capability of AWS Systems Manager, sets and maintains the desired state configuration for managed nodes and AWS resources within your AWS account.
- In a hybrid environment(AWS + on prem), you must create an IAM role for those resources to communicate with the Systems Manager service.
- AWS Systems Manager Automation offers one-click automation for simplifying complex tasks such as creating golden Amazon Machines Images (AMIs) and recovering unreachable EC2 instances.
- The
AWSSupport-ExecuteEC2Rescuedocument is designed to perform a combination of Systems Manager actions, AWS CloudFormation actions, and Lambda functions that automate the steps normally required to use EC2Rescue
Systems Manager Parameter Store
- Secure, hierarchical storage for configuration data management and secrets management.
- You can store values as plain text or encrypted data.
AWS OpsWorks
- The stack is the top-level AWS OpsWorks Stacks entity. It represents a set of instances that you want to manage collectively, typically because they have a common purpose such as serving PHP applications.
- Every stack contains one or more layers, each of which represents a stack component, such as a load balancer or a set of application servers.
- On Linux-based instances in Chef 11.10 or older stacks, run the Update Dependencies stack command.
Infrastructure as Code
CloudFormation
- Model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles, by treating infrastructure as code.
- Template describes your desired resources and their dependencies so you can launch and configure them together as a stack.
- Offers extensibility with CloudFormation Registry to provisiong 3rd party resources(e.g. monitoring from partners).
- CloudFormation StackSets let you provision a common set of AWS resources across multiple accounts and regions, with a single CloudFormation template.
- Supports JSON or YAML.
- Automates provisioning and updating your infrastructure in a safe and controlled manner. You can use Rollback Triggers to specify the CloudWatch alarms that CloudFormation should monitor during the stack creation and update process. If any of the alarms are triggered, CloudFormation rolls back the entire stack operation to a previously deployed state.
- Using ChangeSets, you can preview the proposed changes that CloudFormation intends to make.
- Using Drift Detection, you can keep track of changes to resources outside CloudFormation, making sure you always have the most up-to-date picture of your infrastructure.
- Automatically manages dependencies between your resources during stack management actions. You don’t need to worry about specifying the order in which resources are created, updated, or deleted; CloudFormation determines the correct sequence of actions to take for each resource when performing stack operations.
- Provides a set of application bootstrapping scripts that enable you to install packages, files, and services.
- Can be used with Chef and Puppet, Terraform.
- By default, the “automatic rollback on error” feature is enabled.
- WaitCondition to wait for your app to start, blocking the creation of other resources.
- Intrinsic functions can only be used in specific parts of a template: properties, output, metadata, and update policy.
- With the DeletionPolicy attribute you can preserve, and in some cases, backup a resource when its stack is deleted.To keep a resource when its stack is deleted, specify Retain, You can use retain for any resource. For Snapshot, CloudFormation creates a snapshot of the resource before deleting it.
- Dynamic references provide a compact, powerful way for you to specify external values that are stored and managed in other services, such as the Systems Manager Parameter Store, in your stack templates. Retrieves the value of the specified reference when necessary during stack and change set operations.
- To specify how AWS CloudFormation handles rolling updates for an Auto Scaling group, use the AutoScalingRollingUpdate policy.
AWS CDK
- It’s an open-source software development framework for defining cloud infrastructure as code with modern programming languages and deploying it through AWS CloudFormation.
- When AWS CDK applications are run, they compile down to fully formed CloudFormation JSON/YAML templates that are then submitted to the CloudFormation service for provisioning.
Website and Web App Development
Elastic Beanstalk
- To enable managed platform updates configure the update level and the weekly update period.
- Blue/Green: CodePipeline, CodeDeploy to blue, CodeBuild to test the code in blue env, use lambda after testing to swap URLs between blue/green.
- Immutable deployments perform an immutable update to launch a full set of new instances running the new version of the application in a separate Auto Scaling group alongside the instances running the old version. Immutable deployments can prevent issues caused by partially completed rolling deployments. If the new instances don’t pass health checks, Elastic Beanstalk terminates them, leaving the original instances untouched.
IoT
IoT Greengrass
- Open-source edge runtime and cloud service for building, deploying, and managing device software.
- Makes it easy to bring intelligence to edge devices. Collect, aggregate, filter, and send data locally. Manage and control what data goes to the cloud for optimized analytics and storage.
IoT Core
- Central point of ingress for IoT data. Securely transmit messages to and from all of your IoT devices and applications with low latency and high throughput.
- Connect billions of IoT devices and route trillions of messages to AWS services without managing infrastructure.
IoT Device Management
- Register, organize, monitor, and remotely manage IoT devices at scale.
IoT SiteWise
- Collect, organize, and analyze industrial equipment data.
IoT TwinMaker
- Create digital twins of real-world systems such as buildings, factories, industrial equipment, and production lines.
Other Services
Amazon CloudSearch
- Managed solutions for search functionality of website or app.
- Index and search both structured data and plain text.
- Different types of searches(boolean, range, full text).
Amazon WorkSpaces
- Provision virtual, cloud-based Microsoft Windows or Amazon Linux desktops for your users
- Amazon WorkSpaces Application Manager (Amazon WAM) offers a fast, flexible, and secure way for you to deploy and manage applications for Amazon WorkSpaces with Windows. software deployment, updates, patching, and retirement.